This blog post was automatically translated from the original Dutch using Mistral Vibe.
Sovereign AI has never been more relevant. The US government has subjected Anthropic’s latest LLMs to export restrictions, even after the sharp edges of Mythos had already been smoothed out in the form of Fable. In addition to sparking a wave of entertaining Le Chaton Fat memes in Europe, this has reignited a serious discussion: how can we leverage the positive aspects of AI technology without once again becoming fully dependent on foreign parties?
One of the most frequently cited answers in the Netherlands is GPT-NL. Does this mean the Netherlands finally has an ace up its sleeve? The expectations are high, in every case, especially within the government. Before the model was even released, it had already won the Dutch Privacy Award and the Dutch AI Award for Best Initiative.
Yet, not everyone is equally enthusiastic. Legal expert, researcher, and writer Ot van Daalen wondered last week whether the money spent on GPT-NL was well spent. AI influencer Alexander Klöpping is more blunt: he consigned the entire model to the trash bin, apparently based on experiences he had not previously shared publicly. This earned him a sharp response from TNO media personality Selmar Smit. Meanwhile, even Quote(!) and Hacker News have weighed in.
University lecturer in information retrieval & natural language processing David Graus from the University of Amsterdam and lab manager of the OpenGov lab frequently expresses frustration about the lack of realism and technical depth in public GPT-NL communications. Associate professor in natural language processing, explainable AI, and cognitive modeling Jelle Zuidema from the UvA is less openly critical of GPT-NL and points to its modest goals, but has expressed his disappointment over the lack of collaboration with Dutch research groups.
The arrival of increasingly advanced AI presents the Netherlands with major choices. To make the right decisions for the future, we all need clarity on where we currently stand. For me, this is a good reason to dive deep into the facts. At the transition from development to practical use: have GPT-NL’s stated performance goals already been achieved?
Disclaimer
From 2015 until September 2025, I worked with great pleasure as a machine learning engineer and project leader for the NFI. The NFI is a minor partner in the GPT-NL project, which is led by TNO. Among other roles, I served as the project leader for GPT-NL on the NFI side.
This analysis is based on documents that TNO itself made public after that time. Like the rest of the Netherlands, I have not yet been able to try the GPT-NL model. All interpretations of the documents are my personal responsibility.
GPT-NL
These are exciting times for GPT-NL, the Netherlands’ first publicly funded open / not-so-open language model. Three months ago, TNO announced in the GPT-NL Progress Report #2 that a new phase had begun. “Now, in the first quarter of 2026, a new phase is beginning: from development to practical use,” the announcement stated. “The foundation is solid.”
These are optimistic words from the world’s most idealistic language model project, which has made the involvement of data providers its top priority. The project is proud that only donated and licensed data is used to train the model.
GPT-NL rejects the use of texts from the public internet as a matter of principle, even now that European copyright law permits the use of public internet texts for AI training, as long as paywalls are not bypassed and opt-outs (e.g., from news organizations) are properly respected. The opt-outs have been outlined since last year in the General-Purpose AI Code of Practice of the European Commission. Additionally, the Commission is currently leading a process to develop broadly supported additional opt-out standards with all stakeholders.
These principles are admirable, but they also create a critical weakness: a massive shortage of training data and, consequently, a risk to the model’s performance. Public transparency about the performance of the model, which finished training at the end of 2025, has so far been lacking. Unfortunately, no benchmark result tables can be found in the aforementioned GPT-NL Progress Report #2, which celebrates the transition from development to implementation. Instead, we are left with a glossy layout and enthusiastic interviews. The closest thing to a benchmark score is the statement: “You can already see that the model performs better than older models like ChatGPT-3 on certain tasks, such as summarization.”
Later, we got a little more.
After persistent criticism about the lack of benchmark scores for the model, a new question appeared in the FAQ section on the GPT-NL website:
 A new passage in the Frequently Asked Questions section on the GPT-NL website.
A new passage in the Frequently Asked Questions section on the GPT-NL website.
This is disappointing. It’s a lot of words to say almost nothing concrete about benchmark scores while pretending to answer the question. I don’t know exactly what happened here, but somewhere in TNO’s process, PR jargon seems to have won out over meaningful transparency.
More Than Good Intentions
You can have all the good intentions in the world, but a responsible development process alone is not enough. To deploy a model responsibly, it is essential that it can reliably perform tasks for you. This may be especially true for GPT-NL’s intended applications: the domains where a local, responsible sovereign model is most necessary strongly overlap with domains where even small error margins are unacceptable. Responsible model development with public funds therefore also requires proper accountability for performance.
Fortunately, there is hope. Without fanfare, the first interim benchmarks for GPT-NL were made public at the end of 2025 in the System Architecture Document - Training Pipeline. So it can be done! Kudos to the researchers who must have fought hard internally for this.
The goal for GPT-NL was never to break performance records: the goal was to use public funds to create a responsibly trained language model that the Netherlands can truly benefit from. Has this been achieved according to its own figures?
 The System Architecture - Training Pipeline document v1.0 released by TNO.
The System Architecture - Training Pipeline document v1.0 released by TNO.
Benchmarks
Dutch Benchmarks for LLMs
In 2024, I advocated within the GPT-NL project for more attention to the structured evaluation of Dutch-language models, as this had not yet been included in the project planning. These evaluations could fairly answer whether the GPT-NL project’s goals had been met by the end.
My internal memo was heeded: budget was allocated for an additional work package Evaluation & Benchmarking, and I am grateful for that. As work package lead, I worked with a mixed team of talented researchers from TNO, SURF, and NFI on the GPT-NL budget to improve the benchmarking capabilities of LLMs in Dutch.
Benchmarks allow you to measure the performance of various models in Dutch, not just GPT-NL. They also enable targeted comparisons between models. Additionally, benchmarks have a longer lifespan than models: you can continue using them to evaluate multiple generations of models until they become too easy to distinguish (benchmark saturation).
The agreement is that all developed benchmarks will be fully open-source.
What Exactly Are Benchmarks?
A benchmark is best compared to taking an exam. Suppose you want to know if an LLM is good at a specific task in Dutch. A task could be reading comprehension, determining the sentiment of a text (positive or negative), or summarizing a text.
Just like for humans, you can create an exam that tests this skill as effectively as possible. If you administer this exam to different LLMs, you can compare the models’ results. You can also set a passing score in advance and decide whether to consider a model for deployment based on that.
Good benchmarks require two things: the exams themselves and a way to administer these exams to various models. The exams are also called benchmark datasets. Software to administer exams to different models is called a benchmarking framework.
Note that we were still in the pre-agentic era: each benchmark measures a single, well-defined task. Benchmarks that require a model to chain together various steps, such as programming a new feature in a software package, are out of scope here.
Benchmarks in EuroEval
For GPT-NL, the open-source benchmarking framework EuroEval was chosen. This package allows you to run various language models and already included some Dutch benchmark datasets. Many of the existing datasets are automatically translated from English, which is not ideal. You won’t be able to measure subtle knowledge of Dutch and Dutch culture with these, but you have to start somewhere. EuroEval collects the benchmark results on a leaderboard where models can be compared.
In the Evaluation & Benchmarking work package, better original Dutch benchmark datasets were also collected and created. By contributing these as open-source to EuroEval, anyone in the world can run better Dutch benchmarks. This contribution process is still ongoing, but already publicly contributed datasets (mostly pre-existing) include:
- Logical reasoning: COPA-NL (Choice of Plausible Alternatives)
- Bias detection: MBBQ-NL (Multilingual Bias Benchmark for Question-answering)
- Simplification: Duidelijke taal
- Matching the right proverb to a situation: Dutch Proverbs
A recent GPT-NL presentation also shows work on a benchmark using Dutch civic integration exams. This is good data for testing knowledge of Dutch culture.
Measurable Goals: Measure to Know
What Goals Were Set for GPT-NL?
Developing a language model requires measurable goals, especially when €13.5 million in tax money is involved. The most concrete formulation of the goals for the Netherlands’ sovereign language model can be found in the GPT-NL Definition of Success from November 2025, nearly two years after the project’s start. Ironically, the document is only available in English.
Functionality
The model will perform text generation, summarization, and simplification tasks at a level of performance comparable to the Llama2 7B model and GPT-3 175B (or equivalent) models. Performance will be measured in Dutch, on benchmarks that are publicly available (i.e. in EuroEval). Where we see gaps in the quality or availability of Dutch benchmarks, we will contribute to fill these gaps with benchmarks that we will release publicly. We do not optimize the model for specific benchmarks.
(..)
Instruct-tuned LLM
We see this as being delivered successfully when:
- The model can be used in production by Dutch organizations.
- The model can summarize, simplify, and support information retrieval implementations.
- The model delivers sufficient performance for general tasks, providing a reliable base for domain-specific fine-tuning and further research.
- (..)
GPT-NL Definition of Success, pages 7 and 8.
A Low Bar
So, performance comparable to Llama 2 7B and GPT-3 175B, with a large focus on a small number of narrowly defined tasks. It’s important to realize that in 2026, this is an extremely low bar.
GPT-3 is the 2020 model that formed the basis for the first ChatGPT, after it was first extensively fine-tuned to be a good chatbot. The chatbot was named ChatGPT-3.5 and launched at the end of 2022. Since the launch of ChatGPT, LLMs have made enormous improvements. ChatGPT-3.5 was succeeded within 4 months by GPT-4, a year later by GPT-4o, a year and a half after that by GPT-5, and eight months later by GPT-5.5. Serious competition has also emerged in the form of Anthropic, Mistral, and several Chinese tech companies.
Now, more than 3.5 years and an entire AI revolution later, we have collectively forgotten how poorly ChatGPT-3.5 performed, how much it hallucinated, and how badly it handled tasks like math and logic.
The same applies to the second reference model: Llama 2 7B. It’s a small model: with 7 billion parameters, it’s 10 times smaller than its big brother, Llama 2 70B. Additionally, it’s nearly three years old, produces poor Dutch, and doesn’t excel in intelligence. Try it yourself: Llama-2 7B Chat. Don’t forget to enter a Dutch system prompt.
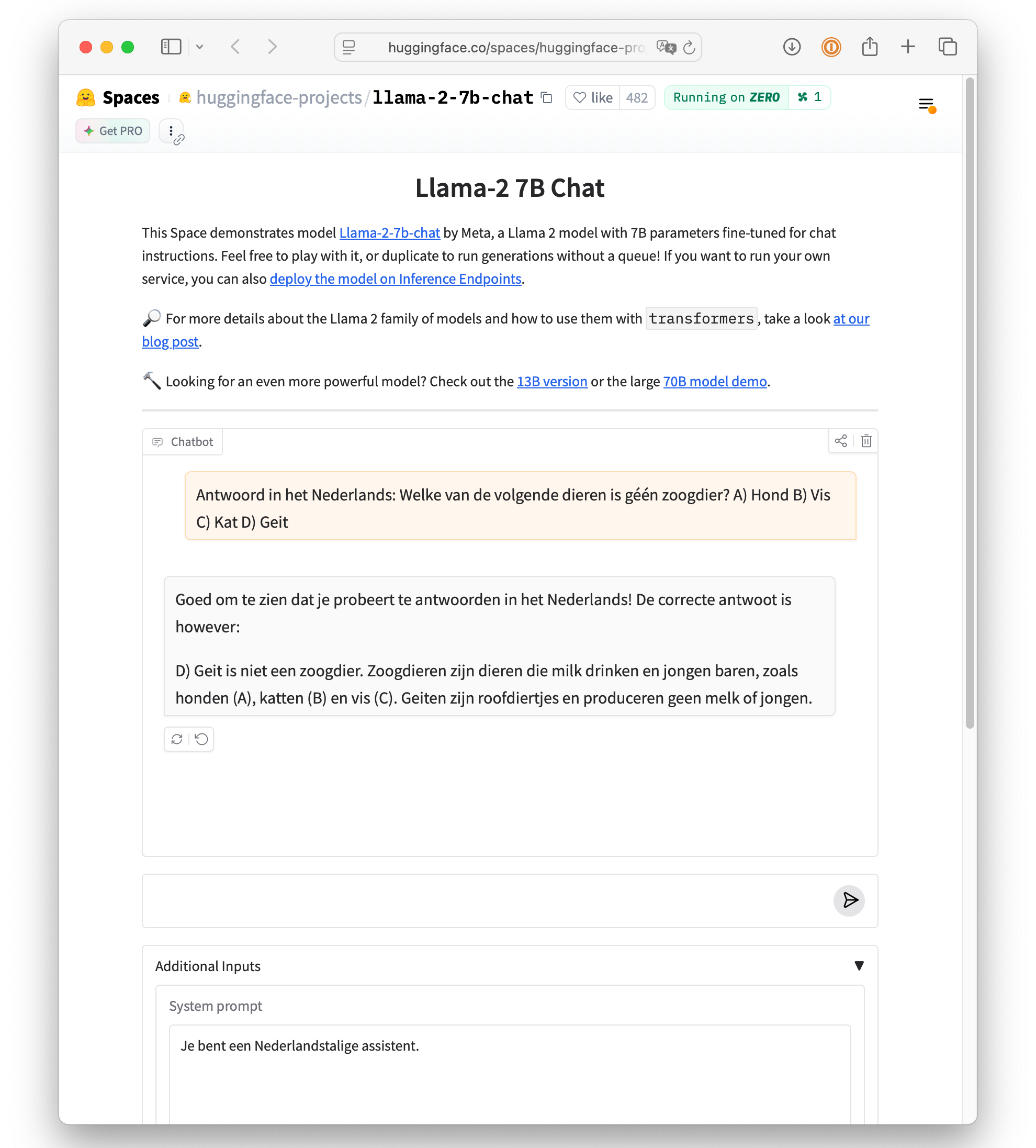 Screenshot of Llama 2 7B in action on HuggingFace. The performance level of Llama 2 7B and GPT-3 175B (or equivalent models) has been set as the benchmark for GPT-NL.
Screenshot of Llama 2 7B in action on HuggingFace. The performance level of Llama 2 7B and GPT-3 175B (or equivalent models) has been set as the benchmark for GPT-NL.
The Results
The Published Benchmark Scores
The published benchmark scores are in the document GPT-NL System Architecture - Training Pipeline v1.0 in the TNO Repository. Since the start of the project, it has been one of the few forms of technical transparency about the model to be released, but at 109 pages, it’s quite in-depth. It describes the technology behind GPT-NL in detail. These are largely the sensible, conservative choices you’d expect from a project that started in 2024: a standard dense 26B Llama 3-based transformer, AdamW as the optimizer, a SentencePiece-based tokenizer with a custom vocabulary. And it also contains benchmark scores for the model.
Remarkably, there has been no attention from GPT-NL for the release of this document. There was no news article, no LinkedIn update, no page on the website. I can’t even find a link to the document anywhere on the website.
 Benchmark scores for GPT-NL. GPT-NL System Architecture document, page 47.
Benchmark scores for GPT-NL. GPT-NL System Architecture document, page 47.
The benchmark results can be found starting on page 46. What we see here are the benchmark scores on the existing benchmark datasets from EuroEval. So these are not yet the improved and additional benchmarks developed in the Evaluation & Benchmarking work package.
We see graphs with scores on benchmarks in Dutch and English for several intermediate steps of the model. In the text after the charts, the scores are also written out, so fortunately we don’t have to read them off the charts themselves. Epoch 2 or 3 means the model has seen the entire training dataset 2 or 3 times. Annealing is the final part of training the foundation model, where performance is improved by reducing the learning rate while high-quality data is provided. “Epoch-3-annealing” is thus the foundation model after it finished training at the end of 2025.
No instruction tuning has yet taken place on the instruct dataset for these models. These benchmark scores are an indication of the quality of the foundation model itself, where almost all computational power has gone. Fortunately, EuroEval accounts for this: the benchmarks are presented with few-shot prompting in a way that even a foundation model can handle.
Small-scale instruction tuning like GPT-NL is planning to do can usually squeeze a bit of extra performance out of a model, but in my experience it rarely causes a fundamental shift in benchmark scores. Scores for the model after three epochs plus instruction tuning will undoubtedly also be available at TNO, but they have not been made public.
The Comparison
A comparison with the stated goals is not yet made in the document, so we have to do it ourselves. We can compare GPT-NL’s scores with its own performance goals: those of Llama 2 7B and GPT-3 175B (or equivalent). Llama 2 7B is open-source available on HuggingFace, so we can simply benchmark it with EuroEval.
The GPT-3 models were never open-sourced, and you can’t pay OpenAI to access them via an API either. Therefore, we take the most equivalent model that has already been benchmarked in EuroEval: GPT-3.5 Turbo-0613. This closed model was previously available for a fee via an API, and EuroEval supports benchmarking both local models and API models.
I still think it’s important to compare with a model that is current in 2026. Yes, a comparison with Claude Opus 4.7 from Anthropic is not fair because there’s no way to deploy it sovereignly without depending on an American cloud provider, as we painfully saw this week with Fable. The recently released and high-scoring Chinese open-weights1 model GLM 5.2 is also not the best comparison material for similar strategic reasons.
But an open-weights model from the European company Mistral: that is a serious alternative to compare with. So I’m also including the scores of Mistral Small 3.2 24B Instruct 2506. The weights are freely available under the open-source Apache 2.0 license, and at 24 billion parameters, it’s slightly smaller than GPT-NL’s 26 billion, so it can be deployed offline on the same infrastructure.
For this comparison, I looked up the scores per benchmark dataset from the public Dutch leaderboard of EuroEval. Both the scores of Llama 2 7B and Mistral Small 3.2 24B are already there. For GPT-3.5 Turbo-0613, it was previously benchmarked on the validation sets of the benchmark datasets instead of the test sets. I can’t re-benchmark the model on the test set because GPT-3.5 Turbo-0613 is no longer offered by OpenAI, not even for a fee. Fortunately, I don’t expect big differences in scores between the two sets.
Since I don’t have access to GPT-NL, I took the scores for GPT-NL from the shown graphs and the discussion thereof starting on page 47 of the GPT-NL System Architecture - Training Pipeline v1.0 document.
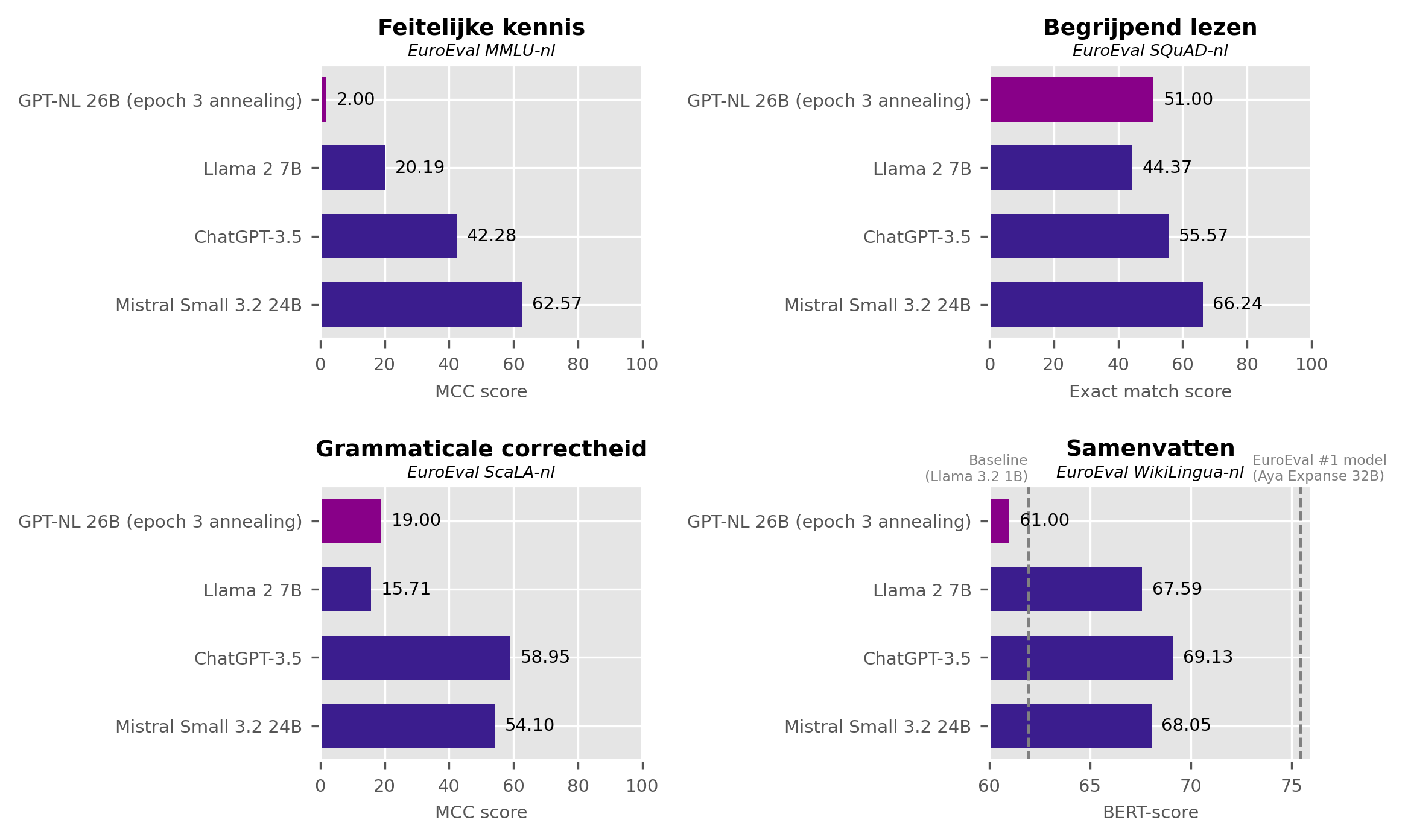
There are seven benchmarks in the graphs, with scores for both the English and Dutch variants. I choose Dutch (as indicated by the Definition of Success) and highlight the four that most closely align with GPT-NL’s stated goals: factual knowledge, reading comprehension, grammatical correctness, and summarization.
Benchmark 1: Factual Knowledge
The first benchmark is a knowledge test on the MMLU-nl benchmark. This is an automatically translated benchmark from the widely used English Massive Multitask Language Understanding benchmark. Topics include mathematics, US history, computer science, law, and more.
Questions are in multiple-choice format:
How can we define energy security?
Answer options:
a. Achieving energy security means ensuring that there are currently sufficient energy sources to maintain current energy consumption and demand worldwide.
b. Energy security refers to the ability of current energy reserves to meet the demands of military consumption by the state, with the military at the center of the security paradigm.
c. Achieving energy security means securing the energy supply needed in the current context and in the future, with regard to foreseeable changes in demand if relevant.
d. Energy security refers to the ability of individuals, economic, and non-state actors to access the energy needed to maintain their growth and development.Example question from MMLU-nl in EuroEval. Correct answer: “c”.
If you only measured how many questions the model gets right, it could still score 25% by pure guessing. Therefore, the benchmark uses the MCC score. This corrects for the guessing chance based on the distribution of correct answers, as is also done in university multiple-choice exams. This way, a model that only guesses gets a score around 0, and a model that answers everything correctly gets a score of 100.
GPT-NL’s score from the document is disappointing: an MCC score of 2 is barely better than guessing. Llama 2 7B does slightly better with a score of 20.19, and ChatGPT-3.5 achieves a score of 42.28. None of them would pass if it were a real exam. Mistral Small 3.2 24B comes in with 62.57, just passing.
On this test, GPT-NL falls far short of the goals.
It’s barely able to answer better than random chance and lags far behind the self-set targets represented by Llama 2 7B and ChatGPT-3.5.

Benchmark 2: Reading Comprehension
Factual knowledge may be less important for the model, as in practice it will often be connected to a search system that first finds the correct information for a user query. This process is called Retrieval-Augmented Generation. You then don’t ask the model to answer from its “own knowledge,” but to answer based on the information found by the search system. At least, that’s the theory you hear when talking to TNO. While there’s something to be said for this when it comes to pure factual knowledge, I still wonder: are you able to give a good answer to a question if you truly have no clue what both the question and the associated search results are about?
It is therefore necessary for the model to be able to read the found information and extract the correct answer to the question from the text. In EuroEval, this task is called Reading Comprehension.
The second benchmark to study is therefore a benchmark suitable for measuring this: SQuAD-nl (Stanford Question Answering Dataset). This dataset is also automatically translated from English, but the translations of the test set were manually improved by eight bachelor’s students.
Text: By comparing diets in Western countries, researchers have discovered that although the French eat more animal fat, the incidence of heart disease in France remains low. This phenomenon is called the French paradox and is assumed to arise from the protective benefits of regularly consuming red wine. Apart from the possible benefits of alcohol itself, including reduced platelet aggregation and vasodilation, polyphenols (e.g., resveratrol), mainly in the grape skin, offer other suspected health benefits, such as:
Answer the following question about the above text in a maximum of 3 words.
Question: What do people in France eat more of than in most Western countries?
Example question from SQuAD-nl in EuroEval. Correct answer: “animal fat”.
How often the model gives the correct answer is measured in two ways: an F1 score on a character basis, which penalizes small mistakes less harshly, and the Exact Match score, which measures the percentage of questions where the given answer exactly matches the correct answer. The table on page 92 reports only the Exact Match score (EM).
GPT-NL’s score is not particularly good: the Exact Match score is 51. It’s not terrible, but if you want to rely on a language model in critical applications to extract the correct information from the Retrieval-Augmented Generation context, I’d still require a higher score. To be fair, it is higher than Llama 2 7B, which scores 44.37. ChatGPT-3.5 does even better than GPT-NL with 55.57, and Mistral Small 3.2 24B wins this round as well with 66.24.
What surprised me is how high the scores of modern small language models are on the EuroEval leaderboard. Even Qwen3.5-0.8B-Base (with 0.8 billion parameters, over 30 times smaller than GPT-NL) scores 56.77, 5 percentage points higher than GPT-NL. I briefly thought I had found a case of benchmaxxing with Qwen, but a few quick tests with recent news articles show that the model can indeed sometimes perform this task reasonably well. Good news for local AI enthusiasts who still have an old Raspberry Pi lying around.
It would be interesting to see GPT-NL’s F1 scores as well, because the Exact Match score can be skewed if a model ignores the instruction to answer in a maximum of 3 words. Even so, this is mostly a problem for models that are optimized for chat. Foundation models that are prompted via few-shot prompting should not suffer from this problem too much. My preliminary conclusion is that the model does not yet perform very convincingly on this benchmark, one of the most important for GPT-NL.

Benchmark 3: Grammatical Correctness
There is still sometimes a misconception about GPT-NL that it will handle the Dutch language better than existing alternatives. Not a strange thought when it comes to a Dutch language model trained in the Netherlands. But reality is more stubborn.
It’s difficult to find large amounts of Dutch-language data, especially if you decide not to use texts from the open internet or Wikipedia. The final training dataset for GPT-NL therefore contains only 10% Dutch texts (less than 55 billion tokens). This includes the major deal with NDP Nieuwsmedia for 23 billion tokens, which is partly responsible for GPT-NL not being released as open source.2
To put those 55 billion tokens of Dutch training data into perspective: the open web crawl dataset HPLT v3.0, EU-subsidized and specially compiled to train European AI models but not used for GPT-NL due to project principles, already contains over 150 billion Dutch tokens. Germany’s brand-new sovereign language model Soofi S is trained on 27 thousand billion tokens.
Llama 3 was trained on 100 times more data: 15 trillion tokens.
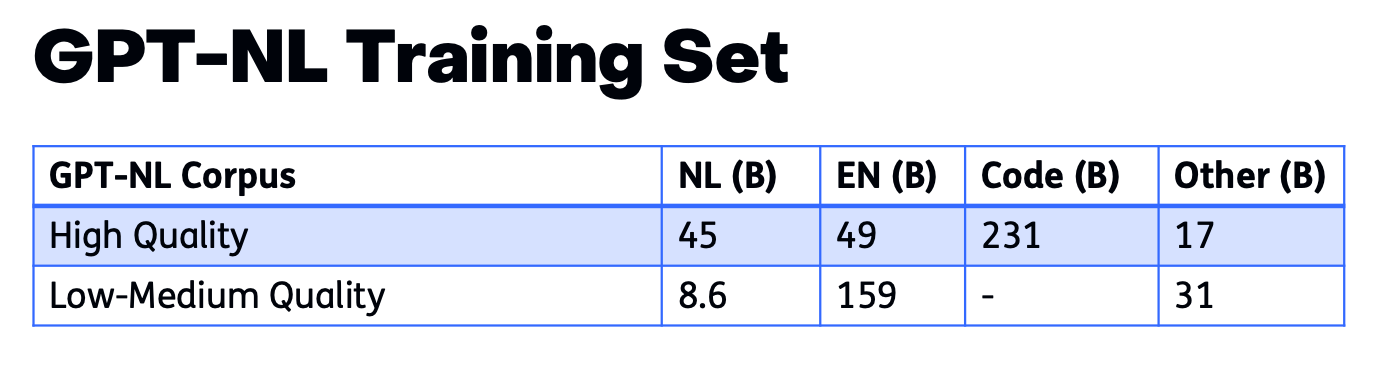 The training data for GPT-NL consists of only 10% Dutch texts. Numbers mentioned are in billions of tokens. Source: Presentation DNB Data Science Event 2025, page 27.
The training data for GPT-NL consists of only 10% Dutch texts. Numbers mentioned are in billions of tokens. Source: Presentation DNB Data Science Event 2025, page 27.
The quality of large parts of the open portion of the GPT-NL dataset is, to put it mildly, not exactly worth writing home about. I’ll have to dedicate another entire blog post to this, but in the meantime, you can get a feel for it by looking at random documents from the GPT-NL Public Corpus below. You can read more about it in the arXiv preprint written about the public dataset.
So it’s important to also test GPT-NL’s language proficiency, which brings us to the third benchmark. The Dutch version of the Scandinavian Linguistic Acceptability dataset (ScaLA-nl) is one way to test a model’s language proficiency.
The dataset consists of Dutch sentences, and the model’s task is to assess for each sentence whether it is grammatically correct or not.
Sentence: Self-governance is also already being introduced in primary schools.
Determine whether the sentence is grammatically correct or not. Answer with ‘yes’ if the sentence is correct and ’no’ if it is not.
Example question from ScaLA-nl in EuroEval. Correct answer: “yes”.
Sentence: Questions, which by a layman not so easily to are.
Determine whether the sentence is grammatically correct or not. Answer with ‘yes’ if the sentence is correct and ’no’ if it is not.
Example question from ScaLA-nl in EuroEval. Correct answer: “no”.
The questions are multiple-choice, but now with only two possible answers: “yes” and “no”. Again, the MCC score is the appropriate metric here. Random guessing yields a score of 0, and getting everything right yields a score of 100.
Unfortunately, the result is similar to that of the knowledge benchmark. With a score of 19, GPT-NL scores better than expected by guessing, but it’s still a deep fail. Llama 2 7B, as we’ve seen before, is also no star in Dutch and remains stuck at 15.71. ChatGPT-3.5 scores the best in this test: 58.95 is a somewhat respectable score. Mistral Small 3.2 24B comes close: it scores 54.10.

Benchmark 4: Summarization
Then there’s summarization: one of the three core tasks the model was developed for.
EuroEval includes the WikiLingua-nl dataset, which consists of texts and reference summaries from the Dutch WikiHow. This is also not an ideal dataset and is certainly open to improvement. In many other languages, there is a benchmark dataset with news articles and corresponding summaries, but unfortunately not for Dutch. The examples from the summarization dataset are too long to include here, but you can view a few in the EuroEval documentation.
Summarization is an interesting task to benchmark. Unlike a multiple-choice exam, the task of summarizing something does not have a single correct answer. You can write quite different summaries that are all “good.”
One solution is to have humans evaluate the summaries generated by the models and assign a score. You can also ask a human to look at two different summaries and decide which one is “better” based on predefined criteria. This is, of course, impractical because we want benchmarks to be automated. It is possible to replace the human with an LLM-as-a-judge, but this also has its drawbacks. LLMs sometimes tend to prefer texts that resemble what they themselves produce, not necessarily the one with the better summary.
Fortunately, the field of natural language processing is much older than Large Language Models. Evaluating summaries is a fairly standard problem. There are therefore many ways to automate this evaluation without involving humans or LLMs.
BERTScore: A Relative Score
Until recently, EuroEval used BERTScore to evaluate a summary based on a reference summary. It’s not perfect, but it can be calculated automatically. It also correlates reasonably well with human evaluations. EuroEval has since switched to the ChrF3++-score, but the results in the TNO report still use BERTScore. Therefore, I also use the BERTScore of the comparison models as they appeared on the EuroEval leaderboard.
A BERTScore must be interpreted differently from, for example, the previously mentioned MCC score. It’s not that a bad summary scores 0 and a perfect summary scores 100. The scores are further from 0 and closer together. If you simply link the scores to a color where 0 is red and 100 is green, all scores will look approximately light green. This mistake is also made in the table on page 92, making the summarization results appear rosy at first glance.
What you should actually do is look at the scores relatively. Let’s start with the highest BERTScore on the Dutch EuroEval leaderboard when it still used BERTScore: the model Aya Expanse 32B scores 75.47. That’s the upper limit. As a lower limit, we take a model we know cannot create good Dutch summaries: the small language model Llama 3.2 1B, which can easily run on a smartphone. It scores 61.94.
So if we want to plot the BERTScores on a graph, we should start at around 60 and end at 76 to get a good picture of the relative scores.
The scores? GPT-NL scores 61, even below the baseline of Llama 3.2 1B that we set for this comparison. The other three models score significantly higher and are also close to each other: Llama 2 7B scores 67.59, ChatGPT-3.5 scores 69.13, and Mistral Small 3.2 24B scores 68.05.
This is best seen in the graph below. Again, GPT-NL scores much lower than the models it was supposed to be comparable to. It is theoretically possible that GPT-NL writes so fundamentally differently from the other models that it skews the benchmark score, but frankly, I don’t think that’s very likely. The statement in Progress Report #2 that GPT-NL already performs better than ChatGPT-3 for summarization is, in any case, not supported by these benchmark figures.
I would like to see some output summaries from the model to qualitatively assess them as well.

Other Benchmarks
One benchmark that is still missing and important for GPT-NL is for text simplification. The evaluation task “simplification” was originally not supported by EuroEval but was added by the GPT-NL project and accepted into the open-source tool. There is also an existing Dutch benchmark dataset: Duidelijke Taal.
Calculating a score for simplification has similar challenges as for summarization, but we won’t get into that here. There are simply no scores for simplification in the System Architecture - Training Pipeline document yet.
What Now?
Benchmarks don’t say everything, but they don’t say nothing either. I find it concerning that the reported scores of the foundation model for factual knowledge and grammatical correctness are barely above random chance. The score for reading comprehension is also unconvincing, and the score for summarization is unusually low. There’s no score to report for simplification yet, but based on the summarization scores, I don’t have high expectations.
 The interim benchmarks relevant to GPT-NL summarized in one figure.
The interim benchmarks relevant to GPT-NL summarized in one figure.
By comparing only with old models, the bar was already very low, but even that bar is not met according to these scores for several important benchmarks. Based solely on these scores, I would have serious doubts about whether the model is ready for practical deployment. At the very least, I would have liked to read something in the Progress Report about these challenges and what is planned to improve performance.
What is the reason for apparently not meeting the goals? A lack of training data would be my first suspect. GPT-NL is trained on far less data than any other modern language model. If that is indeed the limiting factor, then GPT-NL has a big problem. The problem is that it cannot be solved within GPT-NL’s constraints: if you reject data from the open internet and even Wikipedia, there simply isn’t enough data left for a medium-sized language like Dutch. Additionally, collecting even more data under these conditions becomes exponentially harder. After all, you’ve already collected all the large and easy data sources in the past two years. What remains are all the small and difficult data sources.
I don’t want to say anything negative about all the people who have worked on this with so much dedication over the past two years, but the fact remains: you can’t train a successful language model on good intentions alone.
Can we already write off the entire project? Not quite yet. The document also contains images of evaluations with LLM-as-a-judge that still look bad, but somewhat less dramatic. Since the test code for this has not yet been made public, I unfortunately cannot compare them with the performance of ChatGPT-3.5 and Llama 2 7B and thus cannot see if the stated goals are met according to that measurement method.
The scores on the improved Dutch benchmarks developed in the Evaluation & Benchmarking work package also still need to be made public, including the scores for simplification and bias analysis. Maybe there’s still some difference to be seen there. Finally, the model will of course also undergo instruction tuning, but based on the major problems of the foundation model, I expect at most minor improvements from this.
 The timeline for GPT-NL. The training and fine-tuning phases were completed in 2025. Source: GPT-NL Project Planning.
The timeline for GPT-NL. The training and fine-tuning phases were completed in 2025. Source: GPT-NL Project Planning.
Practical Tests
Despite these disappointing numbers, TNO has raised the flag and practical tests have begun. According to Progress Report #2, the Ministry of the Interior and Kingdom Relations is funding3 three Feasibility Studies. For example, ICTU will experiment with GPT-NL for the virtual municipal assistant Gem, a digital assistant is to be created for Overheid.nl, and it will be examined whether letters can be simplified with the communication assistant HIP. This is good news: how useful the model is in practice will become very clear very quickly.
 The three Feasibility Studies funded by the Ministry of the Interior and Kingdom Relations. Source: GPT-NL Progress Report #2, page 10.
The three Feasibility Studies funded by the Ministry of the Interior and Kingdom Relations. Source: GPT-NL Progress Report #2, page 10.
TNO is also starting to work with the model itself, and the NFI, as a partner in the project, is testing the trained model. I have every confidence that my former colleagues from the NFI’s forensic AI team will scrutinize the model down to the bone.
Follow-Up
Meanwhile, explorations are already underway to secure follow-up funding for GPT-NL. In an interview on Tweakers, it is even stated that this will require “at least ten times as much budget.” That would then be at least €135 million.
Apart from the discussion about the lack of European frontier models: it can certainly be valuable to explore how GPT-NL’s opt-in approach can be further developed into more widely applicable models. Not as our sovereign alternative to Fable, but perhaps as a small part of a new Dutch AI strategy that lets a thousand flowers bloom.
What else should we focus on? Consider, for example, more investment in truly open-source European AI, such as EuroLLM and OpenEuroLLM. And are we investing enough in fundamental AI research at Dutch universities? Professor Max Welling advocates for putting the money into an Ellis Institute where startups can emerge. As a country with a medium-sized language, we would in any case benefit greatly from developing new AI architectures that learn much more efficiently from our scarce data than transformers can.
If the Netherlands does decide that GPT-NL needs a publicly funded follow-up, I would ask the subsidizing bodies to get very clear on what the extra money will deliver. How significant are the improvements that can realistically be achieved with more resources? Which bottlenecks will be tackled, and how likely is it that this will succeed? Which goals will be adjusted, and how will they remain measurable? Could external oversight be maintained by independent AI experts who periodically report on progress?
If we don’t remain critical of the returns, we risk GPT-NL becoming a project without an end. After all, not meeting the goals would be a reason to ask for more investment, and meeting the goals would be too.
Either way, the coming period will be crucial for GPT-NL. I hope that all government parties involved in the feasibility studies will publish their detailed test results as soon as possible. And I also hope to see the official benchmark results soon for the version of the model now being deployed in practice.
The Netherlands’ most transparent language model could still use a bit more transparency.
In April, I contacted TNO to ask if more benchmark scores would be published soon for the model now being used in the feasibility studies. More current figures would, of course, make this analysis of the interim scores published by TNO obsolete.
Unfortunately: according to TNO, the benchmarks will only be widely published with the broad rollout of the model at the end of this year. TNO believes that the current interim results (the final scores of the foundation model) are not yet a good representation. These results, according to TNO, are not representative of where the model will be after the feasibility studies and iterative improvements. Unfortunately, how significant the improvements we can expect are is not mentioned.
Further Reading?
- GPT-NL Progress Report #1
- GPT-NL Progress Report #2
- GPT-NL System Architecture Document - Training Pipeline v1.0
- GPT-NL System Architecture Document - Data Curation Pipeline
- GPT-NL Presentation - DNB Data Science Event 2025
- GPT-NL Public Corpus: A Permissively Licensed, Dutch-First Dataset for LLM Pre-training
- Hugging Face – The LLM Evaluation Guidebook
-
An open weights model is a model whose weights (the billions of parameters that, together with the architecture, form the model) are freely available, but unlike open source AI, the underlying datasets and training code are not included in open weights. The Open Source Initiative has a definition of open weights on its website. The GPT-NL model is neither open source nor open weights. ↩︎
-
The Journalism Section of the Auteursbond (Authors’ Union) did have some questions about that deal with two Flemish media conglomerates. For example, it was unclear whether, in addition to the publishers, the actual authors of the pieces would also receive compensation. In a recent interview, it turns out that no solution has yet been found for this. I do give Saskia and Jesse credit for giving an interview to the Auteursbond about this sensitive issue. ↩︎
-
How much TNO is being paid for the Feasibility Studies has not been disclosed, but on LinkedIn, someone received a quote for a feasibility study of €181,000. ↩︎