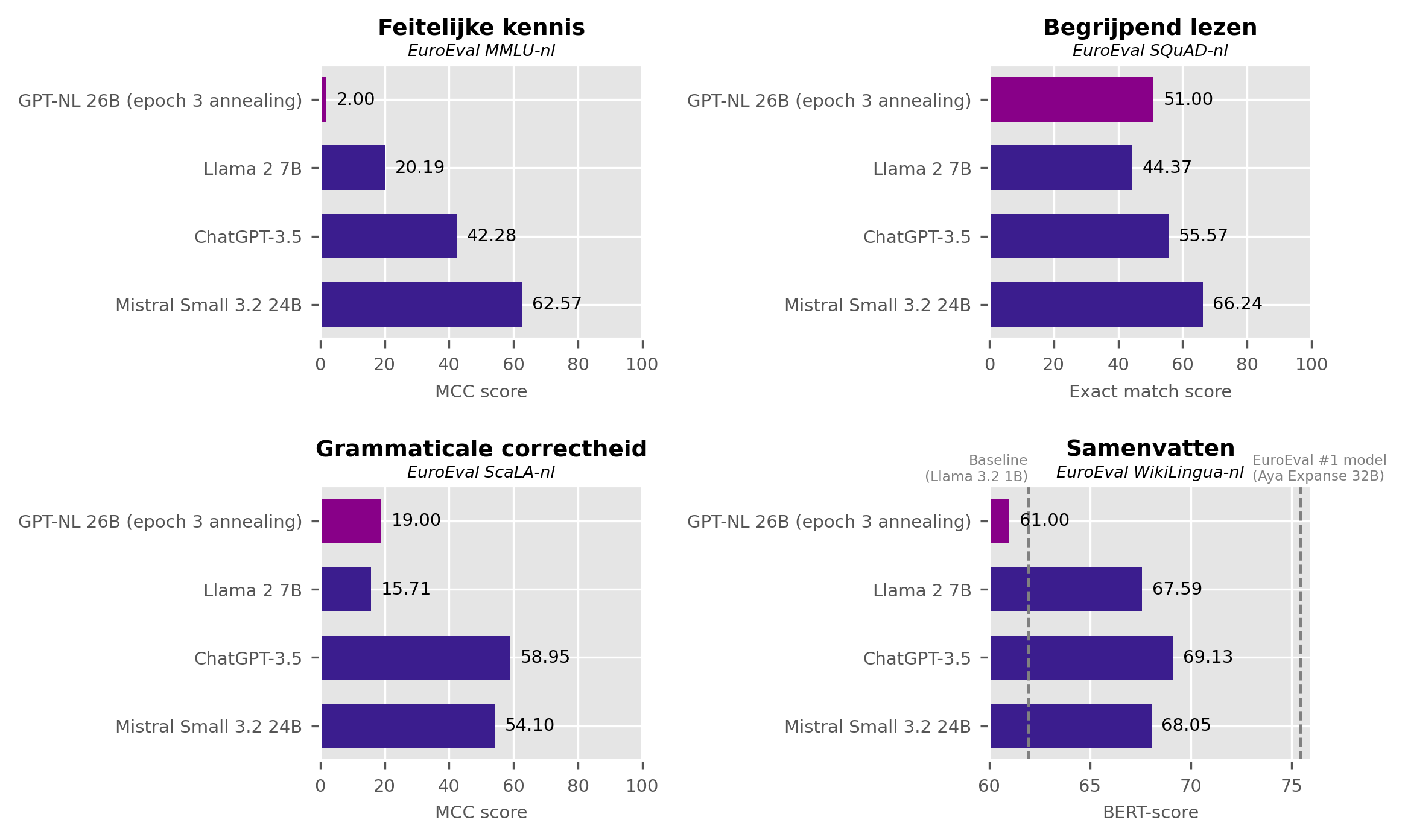
GPT-NL as a Dutch Sovereign Alternative? The Preliminary Benchmarks Don't Look Good
This blog post was automatically translated from the original Dutch using Mistral Vibe. Sovereign AI has never been more relevant. The US government has subjected Anthropic’s latest LLMs to export restrictions, even after the sharp edges of Mythos had already been smoothed out in the form of Fable. In addition to sparking a wave of entertaining Le Chaton Fat memes in Europe, this has reignited a serious discussion: how can we leverage the positive aspects of AI technology without once again becoming fully dependent on foreign parties?...