Soevereine AI is nog nooit zo actueel geweest. De Amerikaanse regering heeft de nieuwste LLMs van Anthropic onderworpen aan exportbeperkingen, ook nadat de scherpe randjes van Mythos er al afgehaald waren in de vorm van Fable. Naast dat het in Europa zorgde voor een hoop vermakelijke Le Chaton Fat memes is daarmee ook de serieuze discussie nogmaals losgebarsten: hoe kunnen we de positieve aspecten van AI-technologie inzetten zonder wéér volledig afhankelijk te raken van buitenlandse partijen?
Eén van de veelgenoemde antwoorden in Nederland is GPT-NL. Daarmee heeft Nederland toch een troef in handen? De verwachtingen zijn in elk geval hoog, zeker binnen de overheid. Voordat het model ook maar is vrijgegeven heeft het al de Nederlandse Privacy Award en de Nederlandse AI Award voor het Beste Initiatief gewonnen.
Toch is niet iedereen even enthousiast: jurist, onderzoeker en schrijver Ot van Daalen vroeg zich vorige week af of het geld aan GPT-NL wel goed besteed is. AI-influencer Alexander Klöpping is stelliger: hij verwijst heel het model resoluut naar de prullenbak, kennelijk op basis van ervaringen waar hij nog niet eerder over gepubliceerd heeft. Dat kwam hem weer op een vinnige reactie te staan van TNO-mediapersoonlijkheid Selmar Smit. Intussen zijn ook de Quote(!) en Hacker News zich ermee gaan bemoeien.
Ook universitair docent information retrieval & natural language processing David Graus van de Universiteit van Amsterdam en tevens labmanager van het OpenGov lab ergert zich regelmatig aan het gebrek aan realisme en technische inhoud van de publieke GPT-NL-communicatie. Universitair hoofddocent natural language processing, explainable AI and cognitive modelling Jelle Zuidema van de UvA is minder openlijk kritisch op GPT-NL en wijst op de bescheiden doelstellingen, maar spreekt wel zijn teleurstelling uit over het gebrek aan samenwerking met Nederlandse onderzoeksgroepen.
De komst van steeds betere AI stelt Nederland voor grote keuzes. Om de goede keuzes voor de toekomst te kunnen maken zijn we allemaal gebaat bij duidelijkheid over waar we nu precies staan. Voor mij een goede aanleiding om eens diep in de feiten te duiken. Bij de overgang van ontwikkeling naar gebruik: zijn de gestelde performance-doelen van GPT-NL al behaald?
Disclaimer
Ik heb van 2015 t/m september 2025 met veel plezier als machine learning engineer en projectleider voor het NFI gewerkt. NFI is een kleine partner in het GPT-NL-project, dat wordt geleid door TNO. Ik was onder andere projectleider voor GPT-NL aan de NFI-kant.
Deze analyse is gebaseerd op documenten die na die tijd door TNO zelf openbaar zijn gemaakt. Het GPT-NL-model heb ik, net zoals de rest van Nederland, nog niet kunnen proberen. Alle interpretaties van de documenten komen voor mijn persoonlijke rekening.
GPT-NL
Het zijn spannende tijden voor GPT-NL, Nederlands eerste publiek gefinancierde open / toch niet open taalmodel. TNO kondigde drie maanden geleden aan in het GPT-NL Progress Report #2 dat een nieuwe fase is aangebroken. “Nu, in het eerste kwartaal van 2026, breekt een nieuwe fase aan: van ontwikkelen naar gebruiken in de praktijk,” aldus de aankondiging. “Het fundament staat stevig.”
Dat zijn optimistische woorden vanuit ’s werelds meest idealistische taalmodelproject dat van de betrokkenheid van dataleveranciers zijn belangrijkste speerpunt heeft gemaakt. Het project is er trots op dat alleen gedoneerde en gelicenseerde data gebruikt wordt om het model te trainen.
GPT-NL wijst het gebruik van teksten van het openbare internet principieel af, ook nu het Europese Auteursrecht het toestaat om teksten van het openbare internet te gebruiken voor het trainen van AI, zolang betaalmuren maar niet omzeild worden en opt-outs (bijvoorbeeld van nieuwsorganisaties) netjes gerespecteerd worden. De opt-outs staan sinds vorig jaar uitgewerkt in de General-Purpose AI Code of Practice van de Europese Commissie. Aanvullend daarop leidt de Commissie momenteel een proces om met alle stakeholders tot breedgedragen aanvullende opt-out-standaarden te komen.
Die principes zijn bewonderingswaardig, maar het zorgt wel voor een ernstige zwakte: een enorm tekort aan trainingsdata en daarmee een risico voor de prestaties van het model. Publieke transparantie over de prestaties van het model dat eind 2025 klaar was met trainen is tot nu toe achtergebleven. Er zijn helaas geen tabellen met benchmarkresultaten te vinden in het eerdergenoemde GPT-NL Progress Report #2 dat de overgang van ontwikkeling naar implementatie viert. In plaats daarvan moeten we het doen met een glossy layout en enthousiaste interviews. Het dichtst in de buurt van een benchmarkscore komt de uitspraak “Je ziet nu al dat het model op bepaalde taken, zoals samenvatten, beter presteert dan oudere modellen als ChatGPT-3”.
Later kregen we iets meer.
Na aanhoudende kritiek op het ontbreken van benchmarkscores van het model verscheen er een nieuwe vraag in de sectie Veelgestelde Vragen op de GPT-NL-website:
 Een nieuwe passage in de sectie Veelgestelde Vragen op de GPT-NL-website.
Een nieuwe passage in de sectie Veelgestelde Vragen op de GPT-NL-website.
Dit is teleurstellend. Het zijn heel veel woorden om nét niets concreets over benchmarkscores te hoeven zeggen, terwijl je toch doet alsof je de vraag beantwoord hebt. Ik weet niet precies wat hier gebeurd is, maar ergens in het proces van TNO lijkt een weinig informatieve PR-tekst het te hebben gewonnen van de betekenisvolle transparantie die gepredikt wordt.
Meer dan goede intenties
Je kunt nog zo veel goede intenties hebben, alléén een verantwoord ontwikkelproces is niet genoeg. Om een model op een verantwoorde manier in te kunnen zetten is het van essentieel belang dat het op een betrouwbare manier taken voor je kan uitvoeren. Dit geldt misschien nog wel dubbel voor de beoogde toepassingen van GPT-NL: de domeinen waar een lokaal, verantwoord soeverein model het meest noodzakelijk is overlappen sterk met de domeinen waar zelfs kleine foutmarges onacceptabel zijn. Bij verantwoorde modelontwikkeling met publiek geld hoort dus ook het deugdelijk afleggen van verantwoording over de prestaties.
Gelukkig is er hoop. Zonder er ruchtbaarheid aan te geven zijn de eerste, tussentijdse benchmarks van GPT-NL eind 2025 publiek gemaakt in het System Architecture Document - Training Pipeline. Het kan dus wel! Hulde aan de onderzoekers die daarvoor intern hard gestreden moeten hebben.
Het doel voor GPT-NL was nooit om performance-records te verslaan: het doel was om met publiek geld een verantwoord getraind taalmodel te maken waar Nederland echt iets aan heeft. Is dat gelukt volgens de eigen cijfers?
 Het door TNO vrijgegeven System Architecture - Training Pipeline document v1.0.
Het door TNO vrijgegeven System Architecture - Training Pipeline document v1.0.
Benchmarks
Nederlandse benchmarks voor LLMs
Ik heb binnen het GPT-NL-project in 2024 gepleit voor meer aandacht voor de gestructureerde evaluatie van Nederlandstalige taalmodellen, omdat daar nog niets voor was opgenomen in de projectplanning. Die evaluaties zouden op een eerlijke manier antwoord kunnen geven op de vraag of de doelstellingen van het GPT-NL-project aan het eind behaald zijn of niet.
Aan mijn interne memo is gehoor gegeven: er is budget vrijgemaakt voor een extra work package Evaluation & Benchmarking en daar ben ik dankbaar voor. Als work package lead heb ik met een gemengd team van getalenteerde onderzoekers van TNO, SURF en NFI op GPT-NL-budget gewerkt aan het verbeteren van de benchmarkmogelijkheden van LLMs in het Nederlands.
Met benchmarks kun je de prestaties van allerlei modellen meten in het Nederlands, niet alleen die van GPT-NL. Ook maakt het gerichte vergelijkingen tussen modellen mogelijk. Daarnaast hebben benchmarks een langere levensduur dan modellen: je kunt ze blijven gebruiken voor het evalueren van meerdere generaties modellen totdat ze te makkelijk zijn geworden om nog een goed onderscheid te kunnen maken (benchmark saturation).
De afspraak is dat alle ontwikkelde benchmarks volledig open source zullen worden vrijgegeven.
Wat zijn benchmarks precies?
Je kunt een benchmark het best vergelijken met het afleggen van een examen. Stel je wilt weten of een LLM goed is in een bepaalde taak in het Nederlands. Een taak kan bijvoorbeeld begrijpend lezen zijn, het bepalen van het sentiment van een tekst (positief of negatief) of het samenvatten van een tekst.
Net zoals voor mensen kun je een examen maken dat die vaardigheid zo goed mogelijk probeert te toetsen. Als je dat examen afneemt bij verschillende LLMs kun je de resultaten van de modellen vergelijken. Ook kun je voor jezelf van tevoren vaststellen welke score je voldoende vindt, en daarmee besluiten om een model wel of niet in overweging te nemen voor inzet.
Voor goede benchmarks heb je twee dingen nodig: de examens zelf en een manier om de examens af te nemen bij allerlei verschillende modellen. De examens worden ook wel benchmark-datasets genoemd. Software om de examens af te nemen bij verschillende modellen heet een benchmarking framework.
Let wel op dat we hier nog in het pre-agentic tijdperk zaten: de benchmarks meten elk een enkele, afgebakende taak. Benchmarks die vereisen dat een model allerlei verschillende stappen zelf aan elkaar rijgt, zoals het programmeren van een nieuwe feature in een softwarepakket, zijn hier buiten scope.
Benchmarks in EuroEval
Voor GPT-NL is ervoor gekozen om het open source benchmarking framework EuroEval in te zetten. Dit pakket biedt de mogelijkheid om allerlei verschillende taalmodellen te draaien, en er zaten ook al wat Nederlandse benchmark-datasets in. Veel van de bestaande datasets zijn automatisch vertaald uit het Engels, wat niet ideaal is. Subtiele kennis van het Nederlands en van de Nederlandse cultuur zul je daar niet mee kunnen meten, maar je moet ergens beginnen. De resultaten van de benchmarks worden door EuroEval verzameld op een leaderboard waarmee modellen met elkaar vergeleken kunnen worden.
In het work package Evaluation & Benchmarking zijn ook betere origineel Nederlandstalige benchmark-datasets verzameld en gemaakt. Door die als open-source bijdrage te doneren aan EuroEval kan iedereen ter wereld betere Nederlandstalige benchmarks draaien. Dat proces van bijdragen loopt nog, maar reeds publiek gemaakte bijdragen zijn de integratie in EuroEval van deze (grotendeels al bestaande) datasets:
- Logisch redeneren: COPA-NL (Choice of Plausible Alternatives)
- Bias-detectie: MBBQ-NL (Multilingual Bias Benchmark for Question-answering)
- Versimpelen: Duidelijke taal
- Het juiste spreekwoord aan een situatie koppelen: Dutch Proverbs
In een recente GPT-NL-presentatie is ook te zien dat er wordt gewerkt aan een benchmark die Nederlandse inburgeringsexamens gebruikt. Dat is goede data om kennis van de Nederlandse cultuur te toetsen.
Meetbare doelen: meten is weten
Welke doelen zijn er gesteld voor GPT-NL?
Bij het ontwikkelen van een taalmodel horen meetbare doelen, zeker als je er 13,5 miljoen euro belastinggeld voor inzet. De meest concrete formulering van de doelen voor het soevereine taalmodel van Nederland is te vinden in de GPT-NL Definition of Success uit november 2025, bijna twee jaar na de start van het project. Het document is ironisch genoeg alleen in het Engels beschikbaar.
Functionality
The model will perform text generation, summarization, and simplification tasks at a level of performance comparable to the Llama2 7B model and GPT-3 175B (or equivalent) models. Performance will be measured in Dutch, on benchmarks that are publicly available (i.e. in EuroEval). Where we see gaps in the quality of availably of Dutch benchmarks, we will contribute to fill these gaps with benchmarks that we will release publicly. We do not optimize the model for specific benchmarks.
(..)
Instruct-tuned LLM
We see this as being delivered successfully when:
- The model can be used in production by Dutch organisations.
- The model can summarize, simplify, and support information retrieval implementations.
- The model delivers sufficient performance for general tasks, providing a reliable base for domain-specific fine-tuning and further research.
- (..)
GPT-NL Definition of Success, pagina’s 7 en 8.
Een lage lat
Performance vergelijkbaar met Llama 2 7B en GPT-3 175B dus, met een grote focus op een kleine aantal nauw gedefinieerde taken. Het is belangrijk om je te realiseren dat dit in 2026 een hele, hele lage lat is.
GPT-3 is het model uit 2020 dat de basis vormde van de eerste ChatGPT, nadát het eerst zeer uitgebreid was doorgetraind om een goede chatbot te zijn. De chatbot kreeg de naam ChatGPT-3.5 en werd gelanceerd eind 2022. Sinds de lancering van ChatGPT hebben LLMs een enorme verbeterslag doorgemaakt. ChatGPT-3.5 werd binnen 4 maanden al opgevolgd door GPT-4, weer een jaar later door GPT-4o, en anderhalf jaar daarna door GPT-5 en acht maanden later door GPT-5.5. Ook is er serieuze concurrentie gekomen in de vorm van Anthropic, Mistral en meerdere Chinese techbedrijven.
Nu, meer dan 3,5 jaar en een hele AI-revolutie later, zijn we collectief vergeten hoe slecht ChatGPT-3.5 presteerde, hoe veel het hallucineerde en hoe slecht het kon omgaan met taken als rekenen en logica.
Hetzelfde geldt voor het tweede referentiemodel: Llama 2 7B. Het is een klein model: met 7 miljard parameters is het 10x zo klein als de grote broer Llama 2 70B. Bovendien is het bijna drie jaar oud, produceert het gebrekkig Nederlands en blinkt het al helemaal niet uit in intelligentie. Probeer het zelf maar eens: Llama-2 7B Chat. Vergeet niet om een Nederlandstalige system prompt in te vullen.
 Screenshot van LLama 2 7B in actie op HuggingFace. Het prestatieniveau van Llama 2 7B en GPT-3 175B (of gelijkwaardige modellen) is vastgesteld als richtniveau voor GPT-NL.
Screenshot van LLama 2 7B in actie op HuggingFace. Het prestatieniveau van Llama 2 7B en GPT-3 175B (of gelijkwaardige modellen) is vastgesteld als richtniveau voor GPT-NL.
De resultaten
De gepubliceerde benchmarkscores
De gepubliceerde benchmarkscores staan in het document GPT-NL System Architecture - Training Pipeline v1.0 in de TNO Repository. Het is sinds de start van het project één van de weinige vormen van technische transparantie over het model die naar buiten zijn gekomen, maar het gaat met 109 pagina’s wel meteen de diepte in. Het beschrijft op een gedetailleerde wijze de technologie achter GPT-NL. Dat zijn grotendeels de zinnige, conservatieve keuzes die je verwacht van een project dat in 2024 startte: een standaard dense 26B Llama 3-gebaseerde transformer, AdamW als optimizer, een op SentencePiece-gebaseerde tokenizer met een custom vocabulaire. En het bevat dus ook benchmarkscores van het model.
Opvallend genoeg is er vanuit GPT-NL geen enkele aandacht geweest voor de vrijgave van dit document. Er was geen nieuwsbericht, geen update op LinkedIn, geen pagina op de website. Ik kan zelfs nergens op de website ook maar een link naar het document ontdekken.
 Benchmarkscores voor GPT-NL. GPT-NL System Architecture document, pagina 47.
Benchmarkscores voor GPT-NL. GPT-NL System Architecture document, pagina 47.
De benchmark-resultaten zijn te vinden vanaf pagina 46. Wat we hier zien zijn de benchmarkscores op de reeds bestaande benchmark-datasets uit EuroEval. Het zijn dus nog niet de verbeterde en aanvullende benchmarks die in het work package Evaluation & Benchmarking ontwikkeld zijn.
We zien grafieken met scores op benchmarks in het Nederlands en in het Engels, voor een aantal verschillende tussenstappen van het model. In de tekst na de grafieken staan de scores ook uitgeschreven, dus we hoeven ze gelukkig niet uit de grafieken zelf af te lezen. Epoch 2 of 3 betekent dat het model de hele trainingsdataset 2 of 3 keer gezien heeft. Annealing is het laatste stukje trainen van het foundation model waarin de performance nog verbeterd wordt door de learning rate af te bouwen terwijl er hoge-kwaliteit data aangeboden wordt. “Epoch-3-annealing” is dus het foundation model nadat het eind 2025 helemaal klaar was met trainen.
Er heeft nog geen instruction tuning plaatsgevonden op de instruct-dataset voor deze modellen. Deze benchmarkscores zijn een indicatie van de kwaliteit van het foundation model zelf, waar bijna alle rekenkracht in is gaan zitten. Gelukkig houdt EuroEval daar rekening mee: de benchmarks worden met few-shot prompting aangeboden op een manier waar ook een foundation model mee om kan gaan.
Kleinschalige instruction tuning zoals GPT-NL van plan is kan meestal nog een beetje extra performance uit een model persen, maar in mijn ervaring veroorzaakt het zelden een grote verschuiving in benchmarkscores. Scores van het model na drie epochs plus instruction tuning zullen ongetwijfeld ook beschikbaar zijn bij TNO, maar ze zijn niet publiek gemaakt.
De vergelijking
Een vergelijking met de gestelde doelen wordt nog niet gemaakt in het document, dus dat moeten we zelf doen. We kunnen de scores van GPT-NL vergelijken met de zelfgestelde performancedoelen: die van Llama 2 7B en GPT-3 175B (of equivalent). Llama 2 7B is open source beschikbaar op HuggingFace, dus die kunnen we gewoon benchmarken met EuroEval.
De GPT-3-modellen zijn nooit open source geworden, en je kunt OpenAI ook niet betalen om ze via een API te benaderen. Daarom nemen we het meest equivalente model dat wel al gebenchmarkt is in EuroEval: GPT-3.5 Turbo-0613. Dit gesloten model was in het verleden tegen betaling beschikbaar via een API, en EuroEval ondersteunt het benchmarken van zowel lokale modellen als API-modellen.
Ik vind het toch belangrijk om ook te vergelijken met een model dat in 2026 wél actueel is. Ja, een vergelijking met Claude Opus 4.7 van Anthropic is niet eerlijk omdat er geen enkele manier is om dat soeverein in te zetten zonder afhankelijk te zijn van een Amerikaanse cloudprovider, zoals we deze week zo pijnlijk hebben gezien bij Fable. Het recent uitgekomen en hoog scorende Chinese open weights1 model GLM 5.2 is om soortgelijke strategische redenen ook niet het beste vergelijkingsmateriaal.
Maar een open weights model van het Europese bedrijf Mistral: dat is toch wel een serieus alternatief waarmee je moet vergelijken. Daarom neem ik de scores van Mistral Small 3.2 24B Instruct 2506 ook mee. De gewichten zijn gratis beschikbaar onder de open source Apache 2.0-licentie, en omdat het met 24 miljard parameters iets kleiner is dan de 26 miljard van GPT-NL kan het offline op dezelfde infrastructuur ingezet worden.
Voor deze vergelijking heb ik de scores per benchmarkdataset van het publieke Nederlandse leaderboard van EuroEval opgezocht. Zowel de scores van Llama 2 7B als Mistral Small 3.2 24B staan daar al op. Voor GPT-3.5 Turbo-0613 geldt dat het in het verleden is gebenchmarkt op de validation sets van de benchmarkdatasets in plaats van op de testsets. Ik kan het model niet opnieuw benchmarken op de testset, omdat GPT-3.5 Turbo-0613 niet meer aangeboden wordt door OpenAI, ook niet tegen betaling. Gelukkig verwacht ik geen grote verschillen in scores tussen de twee sets.
Omdat ik geen toegang heb tot GPT-NL, heb ik de scores voor GPT-NL overgenomen uit de getoonde grafieken en de bespreking daarvan vanaf pagina 47 van het GPT-NL System Architecture - Training Pipeline v1.0 document.
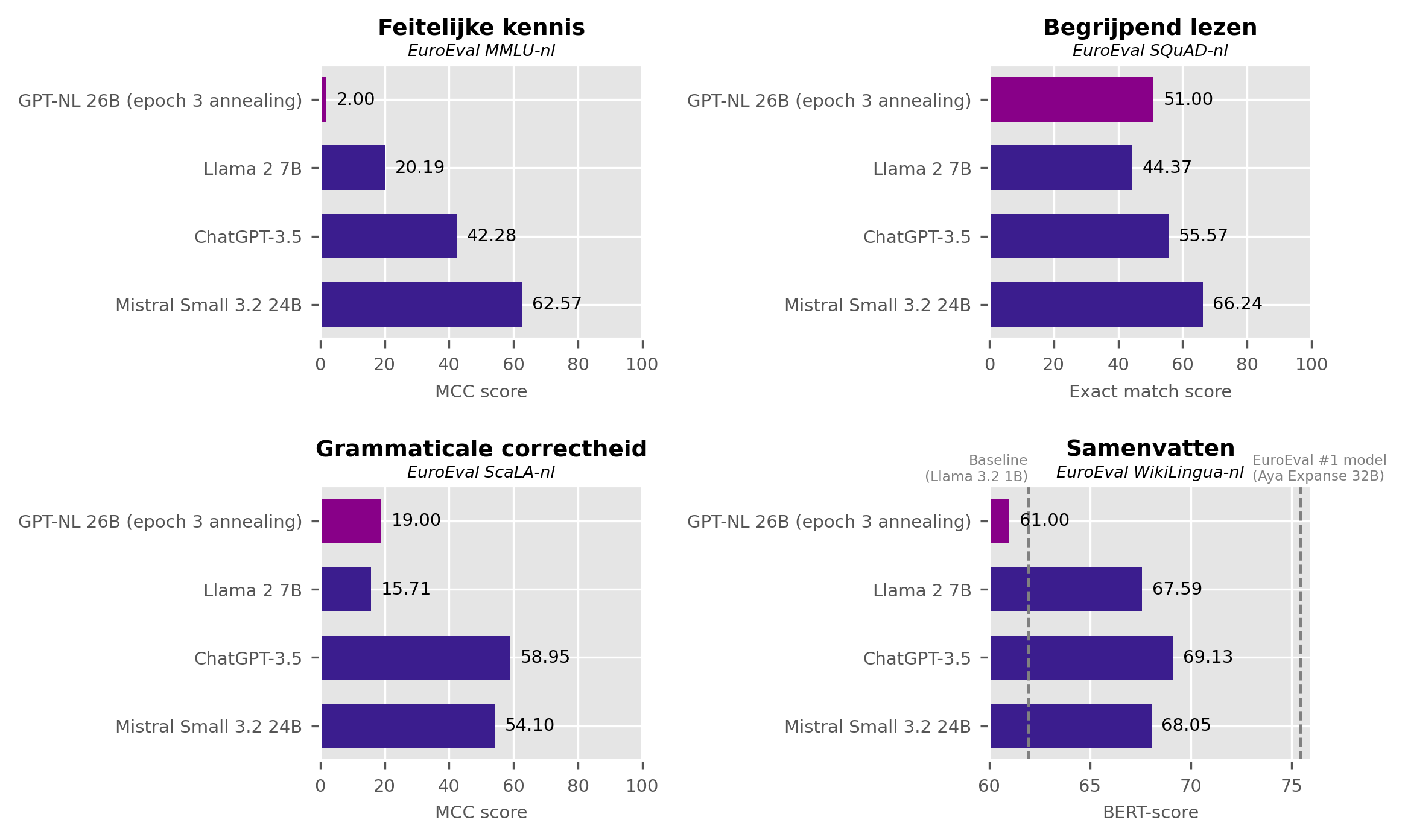
Er staan zeven benchmarks in de grafieken, met scores voor zowel de Engelstalige als Nederlandstalige varianten. Ik kies voor het Nederlands (zoals de Definition of Success aangeeft) en licht er de vier uit die het meest aansluiten op de gestelde doelen voor GPT-NL: feitelijke kennis, begrijpend lezen, grammaticale correctheid en samenvatten.
Benchmark 1: Feitelijke kennis
De eerste benchmark is een kennistest op de MMLU-nl benchmark. Dat is een automatisch vertaalde benchmark van de zeer veelgebruikte Engelstalige Massive Multitask Language Understanding benchmark. Onderwerpen zijn wiskunde, geschiedenis van de VS, computerwetenschappen, recht en meer.
Vragen worden in meerkeuzeformaat gesteld:
Hoe kunnen we energiezekerheid definiëren?
Antwoordopties:
a. Energiezekerheid bereiken betekent ervoor zorgen dat er momenteel voldoende energiebronnen zijn om de huidige consumptie en vraag naar energie wereldwijd te behouden.
b. Energiezekerheid verwijst naar de mogelijkheid van de huidige energievoorraden om te voldoen aan de eisen van militair verbruik door de staat, waarbij het leger centraal staat in het veiligheidsparadigma.
c. Energiezekerheid bereiken betekent het veiligstellen van de energietoevoer die nodig is in de huidige context en in de toekomst, met betrekking tot voorzienbare veranderingen in de vraag indien relevant.
d. Energiezekerheid verwijst naar de mogelijkheid voor individuen, economische en niet-statelijke actoren om toegang te krijgen tot de energie die nodig is voor het handhaven van hun groei en ontwikkeling.Voorbeeldvraag uit MMLU-nl in EuroEval. Correct antwoord: “c”.
Als je alleen zou meten hoeveel vragen het model goed heeft, dan zou het alsnog 25% kunnen scoren door alleen maar te gokken. Daarom wordt voor de benchmark de MCC-score gebruikt. Die corrigeert als het ware voor de gokkans op basis van de verdeling van de goede antwoorden, zoals ook wel bij universitaire multiple-choice-tentamens gebeurt. Zo krijgt een model dat alleen maar gokt een score van rond de 0 en een model dat alles goed beantwoordt een score van 100.
De score van GPT-NL uit het document stelt teleur: een MCC-score van 2 is nauwelijks beter dan gokken. Llama 2 7B doet het al wat beter met een score van 20,19, en ChatGPT-3.5 behaalt een score van 42,28. Geen van alle een voldoende als het een echt examen zou zijn. Mistral Small 3.2 24B komt met 62,57 net uit op een voldoende.
Op deze test haalt GPT-NL de doelen nog lang niet.
Het is nauwelijks in staat beter antwoord te geven dan de gokkans en blijft ver achter bij de zelfgestelde targets die door Llama 2 7B en ChatGPT-3.5 gezet worden.

Benchmark 2: Begrijpend lezen
Feitenkennis is misschien minder belangrijk voor het model, omdat het in de praktijk vaak zal worden aangesloten op een zoeksysteem dat eerst de juiste informatie bij een gebruikersvraag zoekt. Dat proces wordt Retrieval-Augmented Generation genoemd. Je vraagt het model dan niet om te antwoorden vanuit “eigen kennis”, maar om antwoord te geven op basis van de door het zoeksysteem gevonden informatie. Althans: dat is de theorie die je te horen krijgt als je met TNO praat. Hoewel hier iets voor te zeggen valt als het gaat over pure feitenkennis, vraag ik me toch af: ben je in staat om een goed antwoord te geven op een vraag als je werkelijk geen flauw idee hebt waar zowel de vraag als de bijbehorende zoekresultaten over gaan?
Het is dus noodzakelijk dat het model de gevonden informatie kan lezen en het juiste antwoord op de gestelde vraag kan extraheren uit de tekst. In EuroEval heet die taak Reading Comprehension: begrijpend lezen.
De tweede benchmark om te bestuderen is dus een benchmark die geschikt is om dat te meten: SQuAD-nl (Stanford Question Answering Dataset). Ook deze dataset is automatisch vertaald uit het Engels, maar de vertalingen van de testset zijn wel handmatig verbeterd door acht bachelorstudenten.
Tekst: Door diëten in westerse landen te vergelijken, hebben onderzoekers ontdekt dat hoewel de Fransen meer dierlijk vet eten, de incidentie van hartaandoeningen in Frankrijk laag blijft. Dit fenomeen wordt de Franse paradox genoemd en wordt verondersteld te ontstaan door de beschermende voordelen van het regelmatig consumeren van rode wijn. Afgezien van de mogelijke voordelen van alcohol zelf, waaronder verminderde aggregatie van bloedplaatjes en vasodilatatie, bieden polyfenolen (bijv. Resveratrol), voornamelijk in de druivenschil, andere vermoedelijke gezondheidsvoordelen, zoals:
Beantwoord de volgende vraag over de bovenstaande tekst in maximaal 3 woorden.
Vraag: Wat eten mensen in Frankrijk meer van dat in de meeste westerse landen?
Voorbeeldvraag uit SQuAD-nl in EuroEval. Correct antwoord: “dierlijk vet”.
Hoe vaak het model het juiste antwoord geeft wordt op twee manieren gemeten: een F1-score op karakter-basis die kleine foutjes minder hard afstraft en de Exact Match score die meet in welk percentage van de vragen het gegeven antwoord exact overeenkomt met het correcte antwoord. De tabel op pagina 92 rapporteert alleen de Exact Match score (EM).
De score van GPT-NL is niet bijzonder goed: de Exact Match score is 51. Het is niet verschrikkelijk, maar als je erop wilt vertrouwen dat een taalmodel in kritieke applicaties de juiste informatie uit de Retrieval-Augmented Generation context haalt dan zou ik toch een hogere score vereisen. Eerlijk is eerlijk: het is wel hoger dan Llama 2 7B, dat 44,37 scoort. ChatGPT-3.5 doet het nog een stukje beter dan GPT-NL met 55,57, en Mistral Small 3.2 24B wint ook deze ronde met 66,24.
Wat mij verbaasde is hoe hoog de scores van moderne small language models op het EuroEval leaderboard zijn. Zelfs Qwen3.5-0.8B-Base (met 0,8 miljard parameters ruim 30 keer kleiner dan GPT-NL) scoort 56,77, 5 procentpunt hoger dan GPT-NL. Ik dacht even dat ik hier een geval van benchmaxxing van Qwen gevonden had, maar een paar snelle testjes met recente nieuwsartikelen laten zien dat het model deze taak inderdaad af en toe redelijk kan uitvoeren. Goed nieuws voor de liefhebbers van lokale AI die nog een oude Raspberry Pi hebben liggen.
Het zou interessant zijn om ook de F1-scores van GPT-NL te zien, omdat de Exact Match score kan vertekenen als een model de instructie om in maximaal 3 woorden te antwoorden negeert. Al is dit laatste vooral een probleem van modellen die geoptimaliseerd zijn voor chat. Foundation models die met few-shot prompting geprompt worden hebben hier in de regel niet veel last van. Mijn voorlopige conclusie is dat het model op deze benchmark, een van de meest belangrijke voor GPT-NL, nog niet heel overtuigend presteert.

Benchmark 3: Grammaticale correctheid
Over GPT-NL heerst nog weleens de misvatting dat het de Nederlandse taal beter zal hanteren dan bestaande alternatieven. Geen vreemde gedachte als het gaat over een Nederlands taalmodel dat in Nederland getraind wordt. Maar de praktijk is weerbarstiger.
Het is moeilijk om grote hoeveelheden Nederlandstalige data te vinden, zeker als je besluit om geen teksten van het open internet of van Wikipedia te gebruiken. De uiteindelijke trainingsdataset van GPT-NL bevat daarom maar 10% Nederlandstalige teksten (minder dan 55 miljard tokens). Dit is inclusief de grote deal met NDP Nieuwsmedia voor 23 miljard tokens die er mede voor verantwoordelijk is dat GPT-NL niet open source vrijgegeven wordt.2
Om die 55 miljard tokens aan Nederlandstalige trainingsdata in perspectief te zetten: alléén de open webcrawl-dataset HPLT v3.0, door de EU gesubsidieerd en speciaal samengesteld om Europese AI-modellen op te trainen maar vanwege de projectprincipes niet gebruikt voor GPT-NL, bevat al meer dan 150 miljard Nederlandstalige tokens. Het splinternieuwe soevereine taalmodel van Duitsland Soofi S is getraind op 27 duizend miljard tokens.
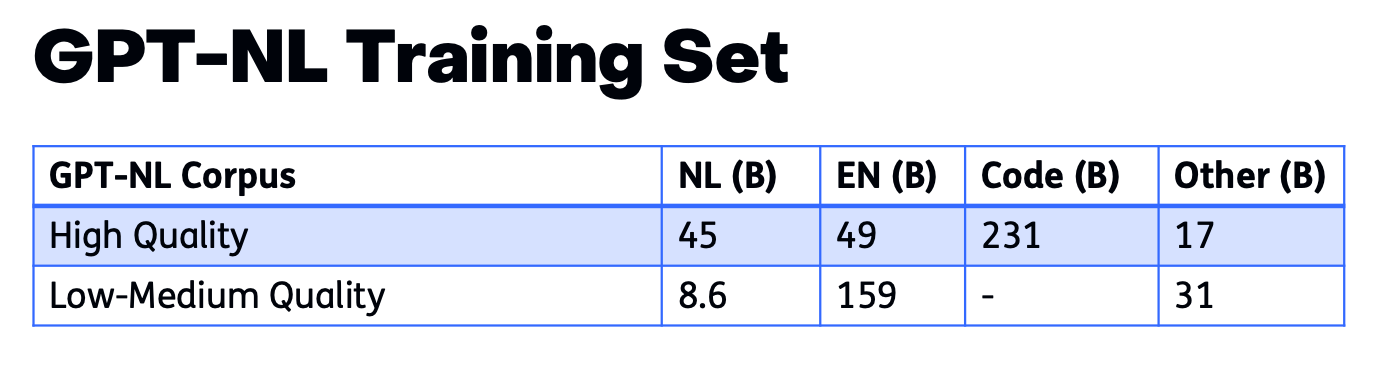 De trainingsdata van GPT-NL bestaat maar voor 10% uit Nederlandstalige teksten. Genoemde getallen zijn in miljarden tokens. Bron: Presentatie DNB Data Science Event 2025, pagina 27.
De trainingsdata van GPT-NL bestaat maar voor 10% uit Nederlandstalige teksten. Genoemde getallen zijn in miljarden tokens. Bron: Presentatie DNB Data Science Event 2025, pagina 27.
De kwaliteit van grote delen van het open gedeelte van de GPT-NL dataset is op zijn zachtst gezegd niet bepaald om over naar huis te schrijven. Ik moet er nog een keer een hele blogpost aan wijden, maar in de tussentijd kan je er een gevoel bij krijgen door hieronder willekeurige documenten uit het GPT-NL Public Corpus te bekijken. Je kunt er meer over lezen in de arXiv preprint die over de publieke dataset geschreven is.
Het is dus zaak om de taalvaardigheid van GPT-NL ook te testen, wat ons bij de derde benchmark brengt. De Nederlandse versie van de Scandinavian Linguistic Acceptability dataset (ScaLA-nl) is één manier om de taalvaardigheid van een model te testen.
De dataset bestaat uit Nederlandse zinnen, en de taak van het model is om van elke zin te beoordelen of deze grammaticaal correct is of niet.
Zin: Met het toepassen van zelfbestuur wordt ook al op de lagere school begonnen.
Bepaal of de zin grammaticaal correct is of niet. Antwoord met ‘ja’ als de zin correct is en ’nee’ als dat niet het geval is.
Voorbeeldvraag uit ScaLA-nl in EuroEval. Correct antwoord: “ja”.
Zin: Vragen, die door een leek niet zo eenvoudig te zijn.
Bepaal of de zin grammaticaal correct is of niet. Antwoord met ‘ja’ als de zin correct is en ’nee’ als dat niet het geval is.
Voorbeeldvraag uit ScaLA-nl in EuroEval. Correct antwoord: “nee”.
De vragen zijn multiple-choice, maar nu met maar twee mogelijke antwoorden: “ja” en “nee”. Wederom is hier de MCC score de aangewezen score. Willekeurig gokken levert een score van 0 op, alles goed hebben een score van 100.
Het resultaat is helaas vergelijkbaar met dat van de kennis-benchmark. Met een score van 19 scoort GPT-NL beter dan bij gokken verwacht wordt, maar het is wel een diepe onvoldoende. Llama 2 7B is, zoals we eerder gezien hebben, ook geen ster in het Nederlands en blijft steken op 15,71. ChatGPT-3.5 scoort het best in deze test: 58,95 is een enigszins respectabele score. Mistral Small 3.2 24B komt daar bij in de buurt: het scoort 54,10.

Benchmark 4: Samenvatten
Dan maar terug naar samenvatten: één van de drie kerntaken waar het model voor ontwikkeld wordt.
EuroEval bevat de dataset WikiLingua-nl die bestaat uit teksten en referentiesamenvattingen van de Nederlandse WikiHow. Ook dit is geen ideale dataset en hij is zeker voor verbetering vatbaar. In veel andere talen is er een benchmarkdataset met nieuwsartikelen en bijbehorende samenvattingen beschikbaar, maar voor het Nederlands helaas niet. De voorbeelden uit de samenvattingdataset zijn te lang om hier op te nemen, maar je kunt er een paar bekijken in de documentatie van EuroEval.
Samenvatten is een interessante taak om te benchmarken. In tegenstelling tot een multiple-choice examen heeft de opdracht om iets samen te vatten niet één correct antwoord. Je kunt behoorlijk verschillende samenvattingen schrijven die allebei “goed” zijn.
Eén oplossing is om de door de modellen gegenereerde samenvattingen te laten beoordelen door een mens, die er een score aan geeft. Ook kun je een mens vragen om twee verschillende samenvattingen te bekijken en te beslissen welke “beter” is, volgens criteria die je van tevoren meegeeft. Dit is natuurlijk onpraktisch om te doen omdat we benchmarks geautomatiseerd willen kunnen draaien. Het is mogelijk om de mens te vervangen door een LLM-as-a-judge, maar dat heeft ook zo z’n nadelen. LLMs willen namelijk nog weleens de voorkeur geven aan teksten die meer lijken op wat ze zelf produceren, niet per se aan welke tekst een inhoudelijk betere samenvatting is.
Gelukkig is het veld van natural language processing al een stuk ouder dan Large Language Models. Het beoordelen van samenvattingen is een vrij standaard probleem. Er zijn dus ook allerlei mogelijkheden om die evaluatie geautomatiseerd te doen zonder mensen of LLMs in te zetten.
BERTScore: een relatieve score
EuroEval maakte tot voor kort gebruik van de BERTScore voor het beoordelen van een samenvatting aan de hand van een referentiesamenvatting. Het is niet perfect, maar wel geautomatiseerd te berekenen. Het correleert ook redelijk met menselijke beoordelingen. EuroEval is intussen overgestapt op de ChrF3++-score, maar de resultaten in het TNO-rapport gebruiken nog de BERTScore. Daarom gebruik ik ook de BERTScore van de vergelijkingsmodellen zoals ze op het EuroEval leaderboard stonden.
Een BERTScore moet je wel anders interpreteren dan bijvoorbeeld eerdergenoemde MCC score. Het is niet zo dat een slechte samenvatting 0 scoort en een perfecte samenvatting 100. De scores liggen verder van 0 af en dichter bij elkaar. Als je de scores simpelweg koppelt aan een kleur waar 0 rood is en 100 groen, dan zullen alle scores er ongeveer lichtgroen uitzien. Die fout wordt ook in de tabel op pagina 92 gemaakt, waardoor het beeld voor samenvattingen er op het eerste gezicht best rooskleurig uitziet.
Wat je eigenlijk moet doen is de scores relatief bekijken. Laten we beginnen met de hoogste BERTScore op het Nederlandse EuroEval leaderboard toen het nog de BERTScore gebruikte: het model Aya Expanse 32B scoort 75,47. Dat wordt de bovengrens. Als ondergrens nemen we een model waarvan we weten dat het niet in staat is om goede Nederlandstalige samenvattingen te creëren: het small language model Llama 3.2 1B dat zonder moeite nog op een smartphone kan draaien. Dat scoort 61,94.
Als we dus de BERTScores in een grafiek willen tekenen, dan moeten we die ongeveer laten beginnen bij een score van 60 en laten eindigen bij 76 om een goed beeld van de relatieve scores te krijgen.
De scores? GPT-NL scoort 61, nog onder de baseline van Llama 3.2 1B die we ons voor deze vergelijking gesteld hebben. De overige drie modellen scoren een stuk hoger en liggen ook dicht bij elkaar: Llama 2 7B scoort 67,59, ChatGPT-3.5 scoort 69,13 en Mistral Small 3.2 24B scoort 68,05.
Dit is het best te zien in onderstaande grafiek. Wederom scoort GPT-NL erg veel lager dan de modellen waarbij het vergelijkbaar zou moeten worden. Het is theoretisch mogelijk dat GPT-NL zo fundamenteel anders schrijft dan de andere modellen dat het de benchmarkscore vertekent, maar eerlijk gezegd acht ik dat niet heel waarschijnlijk. De mededeling in het Progress Report #2 dat GPT-NL nu al beter presteert dan ChatGPT-3 voor samenvatten wordt in elk geval niet door déze benchmarkcijfers gestaafd.
Ik zou wel graag wat output-samenvattingen van het model zien om ze ook kwalitatief te kunnen beoordelen.

Overige benchmarks
Een benchmark die nog mist en voor GPT-NL belangrijk is, is die voor het versimpelen van teksten. De evaluatietaak “versimpelen” werd oorspronkelijk niet ondersteund door EuroEval, maar is door het GPT-NL-project toegevoegd en in de open source tool geaccepteerd. Er hoort ook een bestaande Nederlandstalige benchmarkdataset bij: die van Duidelijke Taal.
Een score berekenen voor versimpelen heeft soortgelijke uitdagingen als voor samenvatten, maar daar komen we hier niet aan toe. Er zijn namelijk nog geen scores voor versimpelen in het System Architecture - Training Pipeline document opgenomen.
Wat nu?
Benchmarks zeggen niet alles, maar ze zeggen ook niet niets. Ik vind het zorgwekkend dat de gerapporteerde scores van het foundation model voor feitelijke kennis en grammaticale correctheid niet ver boven de gokkans uitkomen. De score voor het begrijpend lezen is ook niet overtuigend, en de score voor samenvatten is veel lager dan de modellen die als target dienen. Er is nog geen score te melden voor versimpelen, maar gebaseerd op de scores voor samenvatten heb ik daar geen hoge verwachtingen van.
 De voor GPT-NL relevante tussentijdse benchmarks samengevat in één figuur.
De voor GPT-NL relevante tussentijdse benchmarks samengevat in één figuur.
Door te vergelijken met alleen oude modellen lag de lat al erg laag, maar zelfs die lat wordt volgens deze scores bij meerdere belangrijke benchmarks bij lange na niet gehaald. Op basis van alleen deze scores zou ik ernstige twijfels hebben of het model al klaar is om in de praktijk in te zetten. Op zijn minst had ik iets in het Progress Report willen lezen over deze uitdagingen en wat er gepland staat om de prestaties te verbeteren.
Wat is de reden voor het schijnbaar niet halen van de doelen? Een gebrek aan trainingsdata zou mijn eerste verdachte zijn. GPT-NL wordt getraind op veel minder data dan welk ander modern taalmodel dan ook. Als dat daadwerkelijk de beperkende factor is dan heeft GPT-NL een groot probleem. Het probleem is namelijk niet op te lossen binnen de randvoorwaarden van GPT-NL: als je data van het open internet en zelfs Wikipedia afwijst dan blijft er voor een middelgrote taal als het Nederlands simpelweg te weinig data over. Daarnaast wordt nog meer data verzamelen onder deze voorwaarden exponentieel moeilijker. Alle grote en makkelijke databronnen heb je immers al verzameld in de afgelopen twee jaar. Wat rest zijn alle kleine en moeilijke databronnen.
Ik wil niets ten nadele zeggen van alle mensen die er de afgelopen twee jaar met zo veel inzet aan gewerkt hebben, maar feit blijft: je kunt een succesvol taalmodel nu eenmaal niet trainen op alleen goede bedoelingen.
Kunnen we het hele project dan nu al afschrijven? Nee, dat misschien nog niet. Het document bevat ook plaatjes van evaluaties met LLM-as-a-judge die er nog steeds slecht, maar wel iets minder dramatisch uitzien. Omdat de testcode daarvan nog niet openbaar is kan ik ze helaas niet vergelijken met de prestaties van ChatGPT-3.5 en Llama 2 7B en dus niet zien of de gestelde doelen volgens die meetmethode wél gehaald zijn.
Ook de scores op de verbeterde Nederlandstalige benchmarks die ontwikkeld zijn in het work package Evaluation & Benchmarking moeten nog publiek gemaakt worden, waaronder de scores voor versimpelen en de bias-analyse. Misschien dat daar nog iets van verschil te zien is. Ten slotte wordt het model natuurlijk ook nog met instruction tuning doorgetraind, maar op basis van de grote problemen van het foundation model verwacht ik daarvan hoogstens kleinere verbeteringen.
 De tijdlijn voor GPT-NL. De trainings- en finetuningfases zijn in 2025 afgerond. Bron: Planning van het project GPT-NL.
De tijdlijn voor GPT-NL. De trainings- en finetuningfases zijn in 2025 afgerond. Bron: Planning van het project GPT-NL.
De praktijktests
Ondanks deze teleurstellende cijfers is bij TNO de vlag uit en zijn de praktijktests begonnen. Het Ministerie van Binnenlandse Zaken & Koninkrijksrelaties financiert3 volgens het Progress Report #2 drie Feasibility Studies. Zo gaat ICTU experimenteren met GPT-NL voor de virtuele gemeenteassistent Gem, moet er een digitale assistent komen voor Overheid.nl en wordt er gekeken of brieven versimpeld kunnen worden met de communicatie-assistent HIP. Dit is goed nieuws: hoe bruikbaar het model in de praktijk is zal daar heel snel duidelijk worden.
 De drie door het Ministerie van Binnenlandse Zaken & Koninkrijksrelaties gefinancierde Feasibility Studies. Bron: GPT-NL Progress report #2, pagina 10.
De drie door het Ministerie van Binnenlandse Zaken & Koninkrijksrelaties gefinancierde Feasibility Studies. Bron: GPT-NL Progress report #2, pagina 10.
TNO gaat ook zelf met het model aan de slag, en ook het NFI is als partner in het project het getrainde model aan het testen. Ik heb er gelukkig alle vertrouwen in dat mijn oud-collega’s van het forensische AI-team van het NFI het model tot op het bot zullen doorlichten.
Vervolg
Intussen lopen er al verkenningen om een vervolgproject op GPT-NL gesubsidieerd te krijgen. In een interview op Tweakers wordt zelfs gesteld dat daar “minimaal tien keer zoveel budget voor nodig” is. Dat zou dan minimaal 135 miljoen euro moeten zijn.
Los van de discussie over het ontbreken van Europese frontier models: het kan best waardevol zijn om te verkennen hoe de opt-in aanpak van GPT-NL verder gebracht kan worden tot modellen die breder inzetbaar zijn. Niet als ons soevereine alternatief voor Fable, maar misschien wel als klein onderdeel van een nieuwe Nederlandse AI-strategie die duizend bloemen tegelijk laat bloeien.
Waar moeten we ons dan nog meer op richten? Denk bijvoorbeeld aan meer investeringen in écht open source Europese AI, zoals EuroLLM en OpenEuroLLM. En investeren we wel genoeg in fundamenteel AI-onderzoek bij Nederlandse universiteiten? Hoogleraar Max Welling pleit ervoor om het geld te steken in een Ellis-instituut waar startups uit kunnen ontstaan. Als land met een middelgrote taal zouden we in elk geval veel baat hebben bij het ontwikkelen van nieuwe AI-architecturen die veel efficiënter van onze schaarse data leren dan transformers dat kunnen.
Als we als Nederland toch besluiten dat GPT-NL een publiek gefinancieerd vervolg nodig heeft dan zou ik wel van de subsidiegevende instanties vragen om heel scherp te krijgen wat het extra geld gaat opleveren. Hoe groot zijn de verbeteringen die er met meer middelen realistisch gezien gehaald kunnen worden? Welke bottlenecks worden getackled en hoe waarschijnlijk is het dat dat lukt? Welke doelstellingen worden bijgesteld, en hoe blijven die wel meetbaar? Kan er misschien extern toezicht gehouden worden door onafhankelijke AI-experts die periodiek over de voortgang rapporteren?
Als we niet kritisch blijven op de opbrengst, riskeren we dat GPT-NL een project zonder einde wordt. Het níet behalen van de doelen is dan immers reden om meer investeringen te vragen, en het wél behalen van de doelen ook.
Hoe dan ook, de komende tijd wordt cruciaal voor GPT-NL. Ik hoop dat alle overheidspartijen die bij de feasibility studies betrokken zijn hun gedetailleerde testresultaten zo spoedig mogelijk zullen publiceren. En ik hoop ook graag snel de officiële benchmarkresultaten te zien van de versie van het model dat nu in de praktijk ingezet wordt.
Nederlands meest transparante taalmodel kan immers nog wel wat meer transparantie gebruiken.
Ik heb in april contact opgenomen met TNO om te vragen of er binnenkort nog benchmarkscores gepubliceerd zullen worden van het model dat nu in de feasibility studies ingezet wordt. Actuelere cijfers zouden deze analyse van de door TNO gepubliceerde tussentijdse scores natuurlijk overbodig maken.
Helaas: volgens TNO worden de benchmarks pas breed gepubliceerd bij de brede uitrol van het model eind dit jaar. TNO is van mening dat de huidige tussenresultaten (de eindscores van het foundation model) nog niet een goede weergave zijn. Die resultaten zijn volgens TNO namelijk niet representatief voor waar het model straks na de feasibility studies en iteratieve verbeteringen op uit gaat komen. Hoe groot de verbeteringen zijn die we kunnen verwachten wordt helaas niet vermeld.
Meer lezen?
- GPT-NL Progress Report #1
- GPT-NL Progress Report #2
- GPT-NL System Architecture Document - Training Pipeline v1.0
- GPT-NL System Architecture Document - Data Curation Pipeline
- GPT-NL Presentatie - DNB Data Science Event 2025
- GPT-NL Public Corpus: A Permissively Licensed, Dutch-First Dataset for LLM Pre-training
- Hugging Face – The LLM Evaluation Guidebook
-
Een open weights model is een model waarvan de gewichten (de miljarden parameters die samen met de architectuur het model vormen) vrij beschikbaar zijn, maar in tegenstelling tot open source AI zijn de achterliggende datasets en trainingcode dat bij open weights niet. Het Open Source Initiative heeft een definitie van open weights op zijn website. Het GPT-NL-model is noch open source noch open weights. ↩︎
-
Over die deal met twee Vlaamse mediaconglomeraten had de sectie Journalistiek van de Auteursbond overigens nog wel wat vragen. Zo was onduidelijk of naast de uitgevers de daadwerkelijke auteurs van de stukken ook een vergoeding krijgen. In een recent interview blijkt dat daar nog geen oplossing voor is gevonden. Ik geef Saskia en Jesse wel credits voor het geven van een interview aan de Auteursbond over dit heikele punt. ↩︎
-
Hoeveel TNO betaald krijgt voor de Feasibility Studies is niet bekend gemaakt, maar op LinkedIn heeft iemand een offerte voor een haalbaarheidsstudie gekregen van € 181.000. ↩︎