
Three volunteers. A couple of weeks of work. That’s what it took to add a language to BigScience BLOOM, the open multilingual language model with no fewer than 176 billion parameters that was released mid-2022. It aimed to become an open and multilingual alternative to GPT-3. In the end, 46 languages from all over the world made it into the dataset BLOOM was trained on. Even relatively small languages like Basque and Catalan managed to be included. Dutch did not. How is that possible?
BigScience, big dreams
It all started in 2021. A group of more than 1,000 researchers united in the virtual research collective BigScience. Probably triggered by the capabilities of GPT-3 and concerned about the rise of large language models that were increasingly kept to themselves by big tech companies, they participated from May 2021 in a one-year open research workshop in the field of multilingual large language models.
Funded by the French government and the French-American start-up Hugging Face — one of the hottest companies in the field of AI — they wanted to achieve two things:
- compile a very large multilingual text dataset of high quality, later named ROOTS; and
- train a very large multilingual language model with it that could rival GPT-3: BLOOM.
They wanted to do this as openly as possible. The model had to be downloadable by everyone, so that it could be used for applications where you can’t use closed models like GPT-3. For instance, if you have confidential data that you don’t want to send to some American tech company. Or if you want to investigate the model for possible biases before deploying it. Or if you simply want to know what data the model has and hasn’t seen during the training phase.
To achieve this, the goal was to involve researchers from all sorts of different fields and to examine the dataset and model from multiple perspectives:
During the workshop, the participants plan to investigate the dataset and the model from all angles: bias, social impact, capabilities, limitations, ethics, potential improvements, specific domain performances, carbon impact, general AI/cognitive research landscape.
The whole initiative is also extensively described in three separate scientific papers: about the process, about the dataset, and about the model.
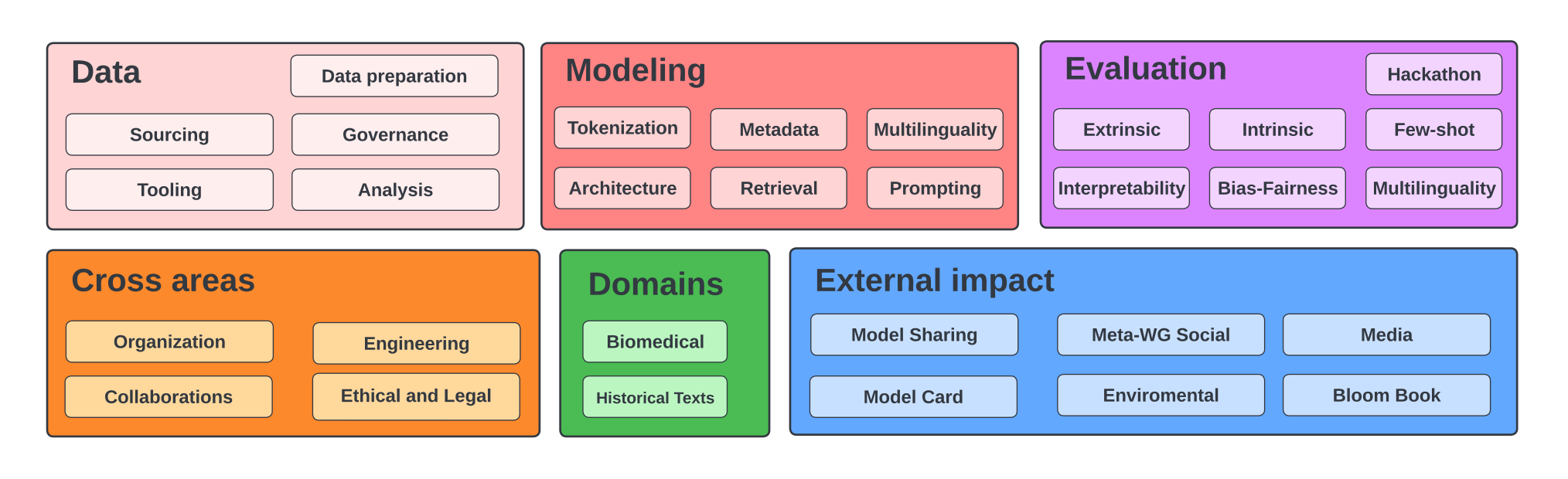 The BigScience working groups. Akiki, Christopher, et al. “BigScience: A case study in the social construction of a multilingual large language model.” arXiv preprint arXiv:2212.04960 (2022).
The BigScience working groups. Akiki, Christopher, et al. “BigScience: A case study in the social construction of a multilingual large language model.” arXiv preprint arXiv:2212.04960 (2022).
BLOOM: open, ethical, and climate-friendly
The result: BLOOM, the BigScience Large Open-science Open-access Multilingual Language Model, launched in July 2022. A large open language model with 176 billion parameters that has been trained in 46 different languages (and 13 different programming languages). It is available for everyone to download, study, and use1. Not only is the final model available, but intermediate checkpoints of the model from during the training have been shared with everyone.
The model was trained in 117 days on more than 3,000 GPUs of the French Jean Zay supercomputer. Cost? About 3 million euros. The French supercomputer is also the source of the claim of the model’s climate friendliness. BigScience proudly states that the required electricity was largely generated by nuclear fission. As a result, the training of the model resulted in low CO2 emissions.
 The Jean Zay Supercomputer. © Photo Library CNRS/Cyril Frésillon
The Jean Zay Supercomputer. © Photo Library CNRS/Cyril Frésillon
The focus on openness and ethics earned praise from the academic world. Researchers from Stanford University recently published a study on large language models. They mapped out which of the large language models already best meet the requirements of the draft text of the European Union’s AI Act. BLOOM scored by far the best. Radboud University also conducted a comparative study on the openness of language models (leaderboard, paper). The most open model? Once again, BLOOM.
In 2022, it became fashionable to consider every large language model as a foundation model, and to fine-tune such a model on chat conversations to create an interactive model similar to OpenAI’s InstructGPT. Therefore, a chat version of BLOOM was also released in early November 2022: BLOOMZ (website, paper, GitHub). Unfortunately, the buzz around it got somewhat lost in the frenzy surrounding ChatGPT, which was launched less than four weeks later.
 Scores of large language models on the requirements of the AI Act. Bommasani, Rishi et al. “Do Foundation Model Providers Comply with the EU AI Act?” https://crfm.stanford.edu/2023/06/15/eu-ai-act.html (2023).
Scores of large language models on the requirements of the AI Act. Bommasani, Rishi et al. “Do Foundation Model Providers Comply with the EU AI Act?” https://crfm.stanford.edu/2023/06/15/eu-ai-act.html (2023).
ROOTS Corpus
In order to train BLOOM, a dataset first had to be assembled: the ROOTS corpus. Here too, the focus was on openness and ethics. Dataset cards were published for all the datasets included in ROOTS. The data itself has been cleaned and deduplicated. Personal private information such as phone numbers, email addresses, and social media usernames have been automatically removed as much as possible. As a result, ROOTS has grown into a dataset of 1.6 terabytes of text data in 46 natural languages, supplemented with 13 different programming languages.
These 46 different languages form quite an interesting mix. Obviously, “high-resource” European languages such as English, French, Spanish, and Portuguese are not missing in this largely European project. In addition, Arabic and Chinese2 are also present. Finally, a number of “low-resource” languages have been deliberately added to the dataset, including several languages from the Niger-Congo language family for which there is little written text available.
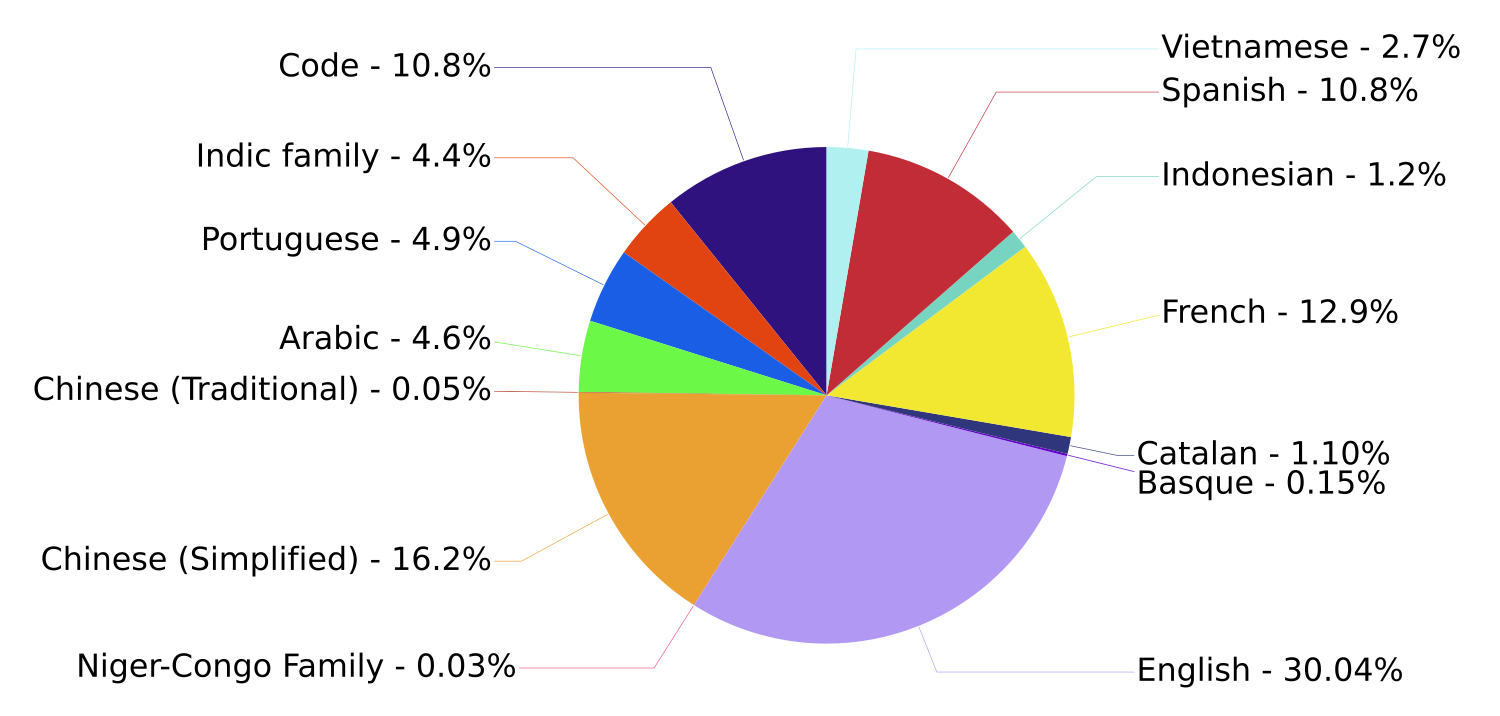 Languages in the ROOTS corpus. Chart from the BLOOM model card.
Languages in the ROOTS corpus. Chart from the BLOOM model card.
Notable missing languages? First and foremost: German. Additionally, Russian, and actually all Slavic languages, as well as the Scandinavian languages. And, of course, Dutch. However, relatively small languages such as Catalan and Basque are included. How can this be?
Language Selection
How was it determined which languages would be included and which would not? The answer is actually quite simple, but strangely enough, it is not found in the paper that describes the ROOTS corpus. Instead, it is discussed in the paper on BLOOM itself, on pages 10 and 11.
Language Choices These considerations led us to an incremental process for choosing which languages were to be included in the corpus. We started with a list of eight of the world’s largest languages by number of speakers for which we did active outreach in the early stages of the project to invite fluent speakers to join the data efforts. Then, on the recommendation of language communities (Nekoto et al., 2020) we expanded Swahili in the original selection to the category of Niger-Congo languages, and Hindi and Urdu to Indic languages (Kunchukuttan et al., 2020). Finally, we proposed that any group of 3 or more participants fluent in an additional language could add it to the supported list if they would commit to selecting sources and guiding processing choices in the language in order to avoid common issues with corpora selected through automatic language identification without specific language expertise (Caswell et al., 2022).
Scao, Teven Le, et al. “Bloom: A 176b-parameter open-access multilingual language model.” arXiv preprint arXiv:2211.05100 (2022)
Volunteers, then. To be precise: at least three volunteers who are fluent in the language and were willing to select sources, and were prepared to ensure that the processing of these sources was done correctly. I don’t know the exact details, but I estimate it at most a few weeks of work. Those were the costs to have the Dutch language benefit from a multi-million euro investment. Apparently, there were not at least three volunteers available who wanted or could do this for Dutch.
Missed Opportunity?
Could it have gone differently? Perhaps. I only heard about the existence of BigScience when it was already too late. Presumably, this is also the case for others in the Netherlands or Belgium who would have liked to contribute. Yes, if I wanted to participate, I would have had to find time somewhere. But with a clear goal in mind and the obvious interest we have as the Netherlands, I probably would have managed. It’s not often that you can benefit from someone else’s million-euro investment with a small time commitment. I probably have spent more time in meetings discussing consortia for hypothetical future Dutch language large language models than it would have taken to add Dutch to BLOOM.
On the other hand: despite all openness, BLOOM has not become the language model that made all other language models obsolete. With 176 billion parameters, it is indeed very large, but BLOOM is from an earlier generation than, for example, Meta’s LLaMA (70 billion parameters), which makes use of its parameters much more efficiently. In the 🤗 Open LLM Leaderboard, a list of the best-performing large language models, BLOOM-178B is not even included. Indicative of the lack of interest from the open-source community, I guess. A smaller variant of BLOOM, BLOOM-7b1 with “only” 7 billion parameters, is present, but it ranked somewhere in the bottom half. BLOOMZ — the chat version of BLOOM — is also not found on the leaderboard.
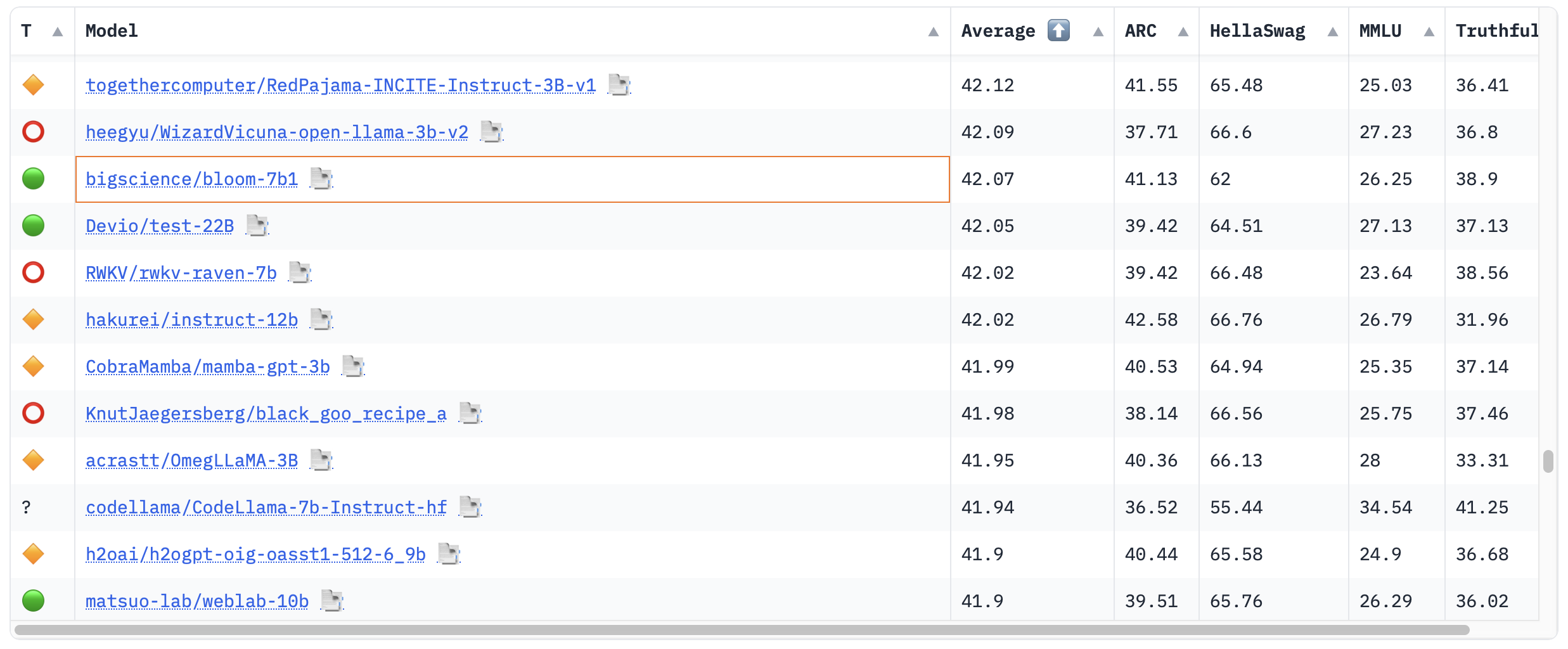 BLOOM-7b1 on the 🤗 Open LLM Leaderboard.
BLOOM-7b1 on the 🤗 Open LLM Leaderboard.
But what does that leaderboard actually measure? Performance in English. The large open language models for Dutch are still very much in their infancy. To my knowledge, such a leaderboard does not even exist for Dutch.3 And if such a leaderboard for open Dutch language models were to exist: a hypothetical BLOOM that had also been trained on Dutch would be at the top of the list. In the lowlands of the blind, one-eyed would be king.
Lessons
What lessons can the Dutch-speaking AI community take from this in my opinion?
To start with: we have to participate. The large American tech companies only see the Netherlands and the Dutch language as a side issue, and who can blame them? As speakers of a small language in a big world, we have to be opportunistic. If we can ride along on an existing initiative: free up capacity and do it! Volunteers wanted? We have them ready! Not just grandiose project plans, but also simple eager hands.
We must prevent being left behind next time. But that alone is not enough. We must, as a country — and therefore as a government — also invest in compiling, cleaning, and publishing Dutch-language datasets. Datasets for training, datasets for creating chatbots and agents, datasets for evaluating performance and measuring bias. We must bring those datasets to everyone’s attention. Publish them everywhere companies and academics looking to train a language model are acquiring their data. So not only on data.overheid.nl and the SURF Repository, but also on Github, on Hugging Face datasets, and on r/MachineLearning. Push our language until it can’t be ignored.
Dutch as something extra on the side. Not by chance, but as a national strategy.
And it doesn’t end there. As a society, we must ask ourselves why our domestic technology companies cannot currently play the same role for Dutch that big tech does for English. Where are the open models of Albert Heijn, Bol.com, Booking.com, and Just Eat Takeaway? And why can the National Growth Fund invest over 200 million euros in the AINed program, but then I find zero developed open-source datasets or models on their website?
And while I’m at it: is there anyone out there even thinking about language models for Frisian?
This post was translated from the original Dutch with the help of GPT-4.
-
Strictly speaking, the model is not open source. It has been released by BigScience under the Responsible AI License (RAIL). This does not impose restrictions on reuse, distribution, commercialization, and modifications, as long as you do not use it for one of the restricted use cases in Appendix A. No need to ask for permission in advance. ↩︎
-
Specifically: written Simplified Chinese ↩︎
-
Any serious attempt to train a large Dutch language model should actually start with compiling datasets with which you could properly evaluate such a model. ↩︎