
Drie vrijwilligers. Een paar weken aan werk. Dat is wat er nodig was om een taal op te nemen in BigScience BLOOM, het open meertalige taalmodel met maar liefst 176 miljard parameters dat halverwege 2022 uitkwam. Het moest een open, meertalig alternatief voor GPT-3 worden. Uiteindelijk zijn er 46 talen van over de hele wereld beland in de dataset waarmee BLOOM getrained is. Ook relatief kleine talen als het Baskisch en het Catalaans kregen het voor elkaar om opgenomen te worden. Het Nederlands niet. Hoe kan dat?
BigScience, big dreams
Het begon allemaal in 2021. Een groep van meer dan 1.000 onderzoekers had zich verenigd in het virtuele onderzoekscollectief BigScience. Vermoedelijk getriggerd door de capaciteiten van GPT-3 en bezorgd om de opkomst van de grote taalmodellen die door de grote techbedrijven voor angstvallig voor zichzelf gehouden worden, deden ze vanaf mei 2021 mee aan een éénjarige open onderzoeks-workshop op het gebied van meertalige grote taalmodellen.
Gefinancierd door de Franse overheid en de Frans-Amerikaanse start-up Hugging Face — één van de hotste bedrijven op het gebied van AI — wilden ze twee dingen bereiken:
- een zeer grote meertalige tekst-dataset samenstellen van hoge kwaliteit, later ROOTS genoemd; en
- daarmee een zeer groot meertalig taalmodel trainen dat GPT-3 naar de kroon kon steken: BLOOM.
Zij wilden dit zo open mogelijk doen. Het model moest door iedereen te downloaden zijn, zodat je het kunt gebruiken voor toepassingen waar je gesloten modellen als GPT-3 niet voor kunt gebruiken. Als je bijvoorbeeld vertrouwelijke data hebt die je niet naar een Amerikaans techbedrijf wil sturen. Of als je het model wilt onderzoeken op mogelijke biases voordat je het inzet. Of als je gewoon uit principe wilt weten op welke data het model wel en niet gezien heeft in de trainingsfase.
Om dit voor elkaar te krijgen zijn onderzoekers betrokken vanuit allerlei verschillende vakgebieden en zijn dataset en model vanuit meerdere gezichtspunten onderzocht:
During the workshop, the participants plan to investigate the dataset and the model from all angles: bias, social impact, capabilities, limitations, ethics, potential improvements, specific domain performances, carbon impact, general AI/cognitive research landscape.
Het hele initiatief is ook uitvoerig beschreven in drie losse wetenschappelijk papers: over het proces, over de dataset en over het model.
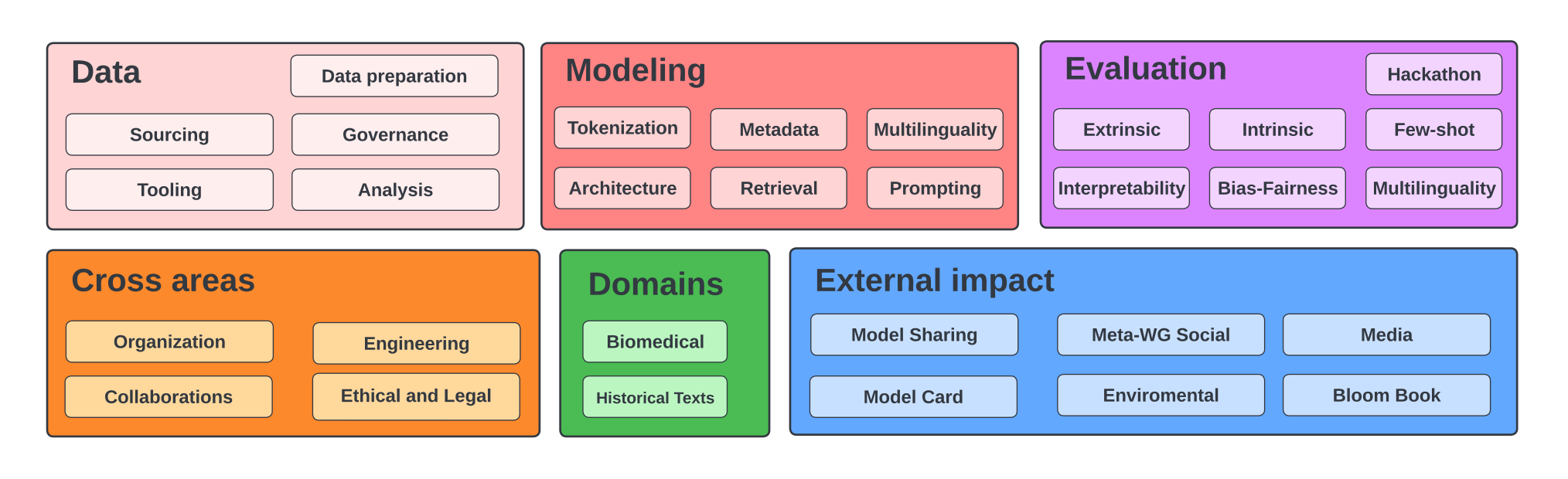 De BigScience werkgroepen. Akiki, Christopher, et al. “BigScience: A case study in the social construction of a multilingual large language model.” arXiv preprint arXiv:2212.04960 (2022).
De BigScience werkgroepen. Akiki, Christopher, et al. “BigScience: A case study in the social construction of a multilingual large language model.” arXiv preprint arXiv:2212.04960 (2022).
BLOOM: open, ethisch en klimaatvriendelijk
Het resultaat: BLOOM, het BigScience Large Open-science Open-access Multilingual Language Model, gelanceerd in juli 2022. Een groot open taalmodel van 176 miljard parameters dat getraind is op 46 verschillende talen (en 13 verschillende programmeertalen). Het is voor iedereen vrij te downloaden, te bestuderen en te gebruiken1. En niet alleen het uiteindelijke model is beschikbaar, maar ook tussentijdse checkpoints van het model van tijdens het trainen zijn met iedereen gedeeld.
Het model is in 117 dagen getraind op ruim 3.000 GPUs van de Franse Jean Zay supercomputer. Kosten? Ongeveer 3 miljoen euro. De Franse supercomputer is ook de bron van de claim van de klimaatvriendelijkheid van het model. BigScience gaat er namelijk prat op dat de benodigde elektriciteit grotendeels opgewekt is met kernenergie. Het trainen van het model heeft daardoor een lage CO2-uitstoot met zich meegebracht.
 De Jean Zay Supercomputer. © Photothèque CNRS/Cyril Frésillon
De Jean Zay Supercomputer. © Photothèque CNRS/Cyril Frésillon
De focus op openheid en ethiek leverde lof op vanuit de academische wereld. Onderzoekers van de Stanford University publiceerden recent een onderzoek naar grote taalmodellen. Ze brachten in kaart welke van de grote taalmodellen nu al het best voldoen aan de eisen uit de voorlopige tekst van de EU AI Act: de Verordening Kunstmatige Intelligentie van de Europese Unie. BLOOM scoorde verreweg het best. Ook de Radboud Universiteit deed een vergelijkend onderzoek naar de openheid van taalmodellen (leaderboard, paper). Het meest open model? Wederom BLOOM.
In 2022 werd het mode om elk groot taalmodel als een foundation model te beschouwen, en zo’n model te finetunen op chatconversaties om een interactief model te maken á la OpenAI’s InstructGPT. Begin november 2022 is er daarom ook nog een chat-variant van BLOOM uitgebracht: BLOOMZ (website, paper, GitHub). De buzz daaromheen is helaas een beetje verloren gegaan in het geweld van ChatGPT, dat nog geen vier weken later werd gelanceerd.
 Scores van grote taalmodellen op de eisen uit de AI-Act. Bommasani, Rishi et al. “Do Foundation Model Providers Comply with the EU AI Act?” https://crfm.stanford.edu/2023/06/15/eu-ai-act.html (2023).
Scores van grote taalmodellen op de eisen uit de AI-Act. Bommasani, Rishi et al. “Do Foundation Model Providers Comply with the EU AI Act?” https://crfm.stanford.edu/2023/06/15/eu-ai-act.html (2023).
ROOTS-corpus
Om BLOOM te kunnen trainen moest er eerst een dataset samengesteld worden: het ROOTS-corpus. Ook hier weer lag de focus op openheid en ethiek. Van alle datasets die in ROOTS zijn opgenomen werden dataset cards gepubliceerd. De data zelf is opgeschoond en gededupliceerd. Persoonsgegevens als telefoonnummers, e-mailadressen en usernames op social media zijn zo veel mogelijk automatisch verwijderd. Zo is ROOTS uitgegroeid tot een dataset van 1,6 terabyte aan tekstdata in 46 natuurlijke talen, aangevuld met 13 verschillende programmeertalen.
Die 46 verschillende talen vormen een nogal interessante mengelmoes. Uiteraard ontbreken high-resource Europese talen als Engels, Frans, Spaans en Portugees niet in dit toch grotendeels Europese project. Daarnaast maken ook Arabisch en Chinees2 acte de présence. Tenslotte zijn er bewust een aantal low-resource-talen aan de dataset toegevoegd, zoals meerdere talen uit de Niger-Congo-taalfamilie waarvoor maar weinig geschreven tekst beschikbaar is.
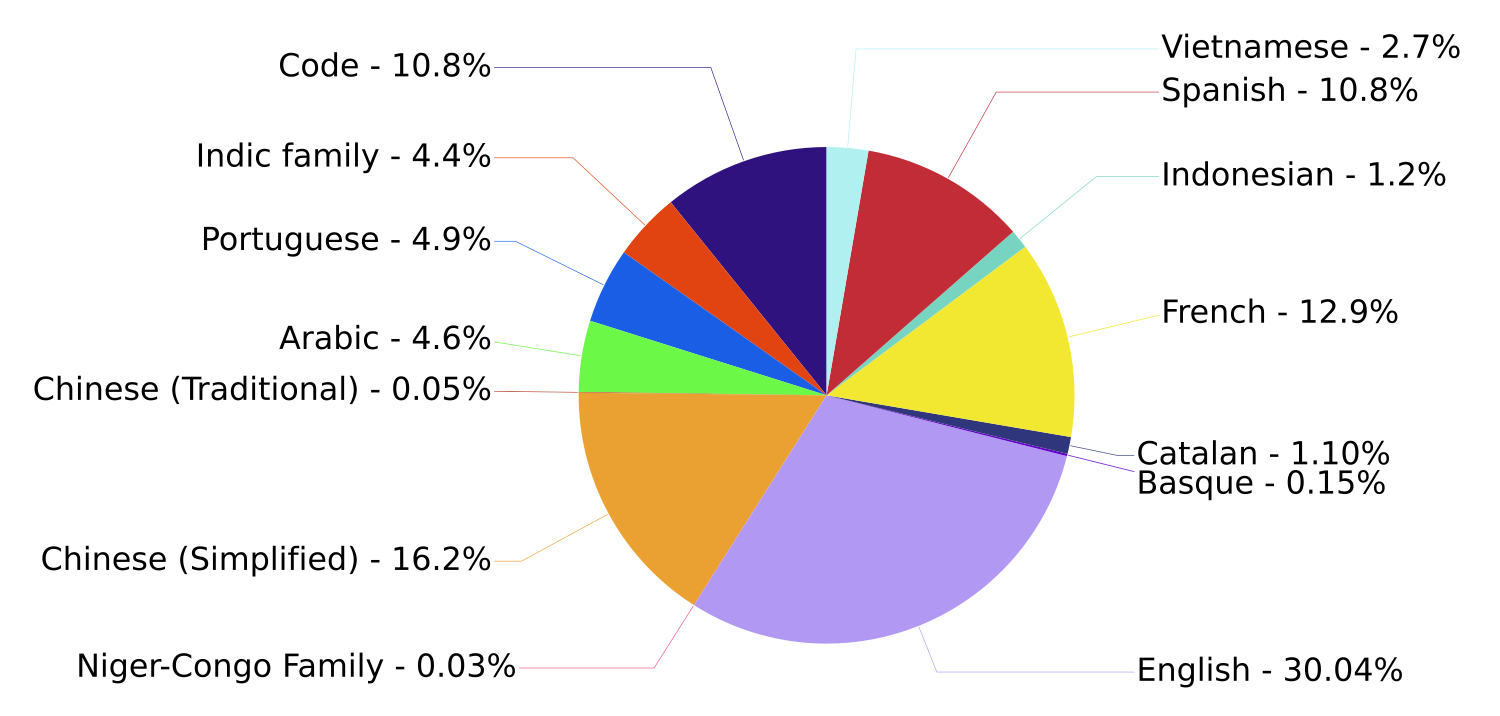 Talen in het ROOTS-corpus. Grafiek uit de BLOOM model card.
Talen in het ROOTS-corpus. Grafiek uit de BLOOM model card.
Opvallende ontbrekende talen? Allereerst: het Duits. Daarnaast het Russisch, en eigenlijk alle Slavische talen, net als de Scandinavische talen. En het Nederlands dus. Wel aanwezig: relatief kleine talen als het Catalaans en het Baskisch. Hoe kan dat?
Taalselectie
Hoe werd bepaald welke talen wel en welke talen niet meegenomen werden? Het antwoord is eigenlijk vrij simpel, maar vreemd genoeg niet te vinden in het paper dat het ROOTS-corpus beschrijft. In plaats daarvan komt het aan bod in het paper van BLOOM zelf, op pagina 10 en 11.
Language Choices These considerations led us to an incremental process for choosing which languages were to be included in the corpus. We started with a list of eight of the world’s largest languages by number of speakers for which we did active outreach in the early stages of the project to invite fluent speakers to join the data efforts. Then, on the recommendation of language communities (Nekoto et al., 2020) we expanded Swahili in the original selection to the category of Niger-Congo languages, and Hindi and Urdu to Indic languages (Kunchukuttan et al., 2020). Finally, we proposed that any group of 3 or more participants fluent in an additional language could add it to the supported list if they would commit to selecting sources and guiding processing choices in the language in order to avoid common issues with corpora selected through automatic language identification without specific language expertise (Caswell et al., 2022).
Scao, Teven Le, et al. “Bloom: A 176b-parameter open-access multilingual language model.” arXiv preprint arXiv:2211.05100 (2022)
Vrijwilligers dus. Om precies te zijn: minimaal drie vrijwilligers die de taal vloeiend spreken en bereid waren om bronnen te selecteren, én bereid waren om te bewaken dat het verwerken van die bronnen op een goede manier gebeurde. Ik weet de details niet precies, maar ik schat het op hooguit enkele weken aan werk. Dat waren de kosten om als Nederlands mee te profiteren van een miljoeneninvestering. Blijkbaar waren er niet minimaal drie vrijwilligers beschikbaar die dat voor het Nederlands wilden of konden doen.
Gemiste kans?
Had het ook anders kunnen lopen? Misschien wel. Ik hoorde zelf pas van het bestaan van BigScience toen het al te laat was. Vermoedelijk geldt dit ook voor anderen in Nederland of België die er graag aan hadden bijgedragen. Ja, als ik mee had willen doen had ik ergens die tijd vandaan moeten halen. Maar met een helder doel voor ogen en met het duidelijke belang dat we er als Nederland mee hebben was het vast wel gelukt. Het is niet vaak dat je met een kleine tijdsbesteding mee kunt liften op andermans miljoeneninvestering. Ik heb waarschijnlijk al langer in vergaderingen gezeten over consortia voor hypothetische toekomstige Nederlandstalige grote taalmodellen dan ik nodig gehad zou hebben om het Nederlands aan BLOOM toe te voegen.
Aan de andere kant: alle openheid ten spijt is BLOOM nou ook weer niet hét taalmodel geworden dat alle andere taalmodellen heeft doen vergeten. Met 176 miljard parameters is het inderdaad heel groot, maar BLOOM is van een eerdere generatie dan bijvoorbeeld LLaMA van Meta (70 miljard parameters), dat een stuk efficiënter met de parameters omgaat. In de 🤗 Open LLM Leaderboard, een ranglijst van best presterende grote taalmodellen, is BLOOM-178B niet eens opgenomen. Tekenend voor het gebrek aan interesse van de open source community, schat ik zo in. Een kleinere variant van BLOOM, BLOOM-7b1 met “maar” 7 miljard parameters, staat wel op de lijst, maar bevindt zich ergens in de onderste helft. BLOOMZ — de chatversie van BLOOM — komt ook niet op het leaderboard voor.
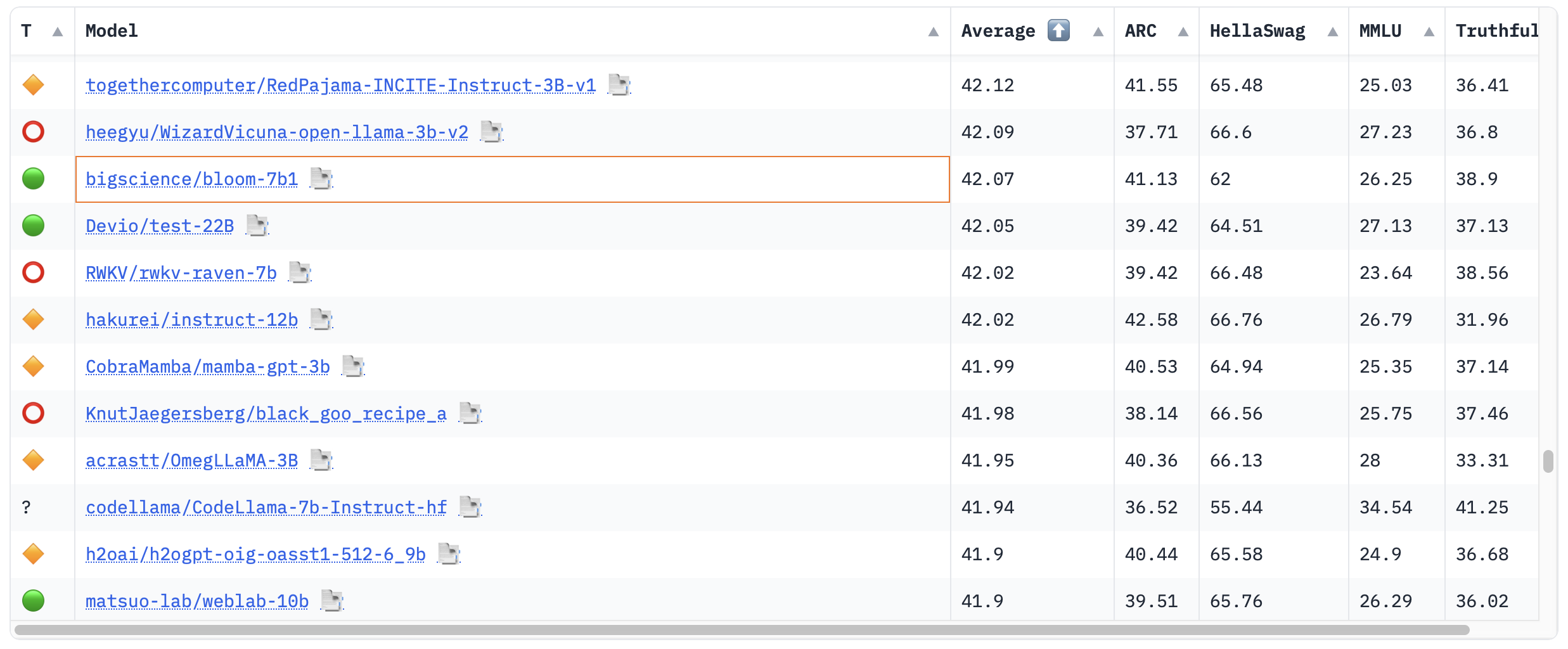 BLOOM-7b1 op het 🤗 Open LLM Leaderboard.
BLOOM-7b1 op het 🤗 Open LLM Leaderboard.
Maar wat meet dat leaderboard eigenlijk? Prestaties in het Engels. De grote open taalmodellen voor het Nederlands staan nog heel erg in de kinderschoenen. Er bestaat naar mijn weten niet eens zo’n leaderbord voor het Nederlands.3 En als er al een leaderboard zou bestaan voor open Nederlandstalige modellen: een hypothetische BLOOM dat ook op het Nederlands getraind zou zijn zou bovenaan de lijst prijken. In de lage landen der blinden zou éénoog koning zijn.
Lessen
Welke lessen kan de Nederlandstalige AI-community wat mij betreft hieruit trekken?
Om te beginnen: we moeten méédoen. De grote Amerikaanse techbedrijven zien Nederland en het Nederlands slechts als bijzaak, en geef ze eens ongelijk. Als sprekers van een kleine taal in een grote wereld moeten we opportunistisch zijn. Als we kunnen meeliften op een bestaand initiatief: capaciteit vrijmaken en doen! Vrijwilligers gezocht? Wij hebben ze klaarstaan! Niet alleen grootse projectplannen, maar vooral ook ijverige handjes.
We moeten voorkomen dat we een volgende keer weer de boot missen. Maar dat alleen is niet genoeg. We moeten als land — en dus als overheid — ook investeren in het samenstellen, opschonen en publiceren van Nederlandstalige datasets. Datasets voor het trainen, datasets voor het maken van chatbots en agents, datasets om prestaties te evalueren en om bias te meten. We moeten die datasets overal onder de aandacht brengen. Publiceren op alle plekken waar bedrijven en academici die een taalmodel willen trainen op zoek zijn naar data. Dus niet alleen op data.overheid.nl en de SURF Repository, maar ook op Github, op Hugging Face datasets en op r/MachineLearning. Pushen tot je er niet meer omheen kunt.
Nederlands als bijvangst. Niet per ongeluk, maar als nationale strategie.
En daar houdt het niet op. Als maatschappij moeten we ons afvragen waarom technologiebedrijven van eigen bodem momenteel niet dezelfde rol kunnen spelen voor het Nederlands die big tech wel speelt voor het Engels. Waar zijn de open modellen van Albert Heijn, Bol.com, Booking.com en Thuisbezorgd? En waarom kan het Nationaal Groeifonds wel meer dan 200 miljoen euro steken in het AINed-programma, maar kan ik vervolgens op hun website nul ontwikkelde open source datasets of modellen vinden?
En als ik dan toch bezig ben: denkt er überhaupt nog iemand aan taalmodellen voor het Fries?
-
Strict gezien is het model niet open source. Het is door BigScience vrijgegeven onder de Responsible AI License (RAIL). Die stelt géén restricties aan hergebruik, distributie, commercialisering en aanpassingen, zolang je het maar niet inzet voor één van de restricted use cases in Appendix A. Van tevoren toestemming vragen is niet nodig. ↩︎
-
Specifiek: geschreven Vereenvoudigd Chinees ↩︎
-
Elke serieuze poging om een groot Nederlandstalig taalmodel te trainen zou eigenlijk moeten beginnen met het samenstellen van datasets waarmee je zo’n model fatsoenlijk zou kunnen evalueren. ↩︎