“Data!”
I always give the same answer when I’m asked what kind of investments are needed to further support Dutch-language AI. Data.
GPUs are nice, but for that I don’t need to be in Groningen. I can already make use of existing European “AI factories” such as the MareNostrum5 supercomputer in Barcelona. What we really need is high-quality, large-scale Dutch-language data. And that’s exactly what they don’t have in Barcelona.
Every public investment in open Dutch-language data strengthens the entire Dutch AI ecosystem and pays for itself many, many times over. It’s a far better investment than hanging even more GPUs in a data center or setting up yet another “data space” website to recycle existing datasets once again behind a login wall.
So what kind of data should you create, and how do you get it? Well, take a look at what the French are doing.
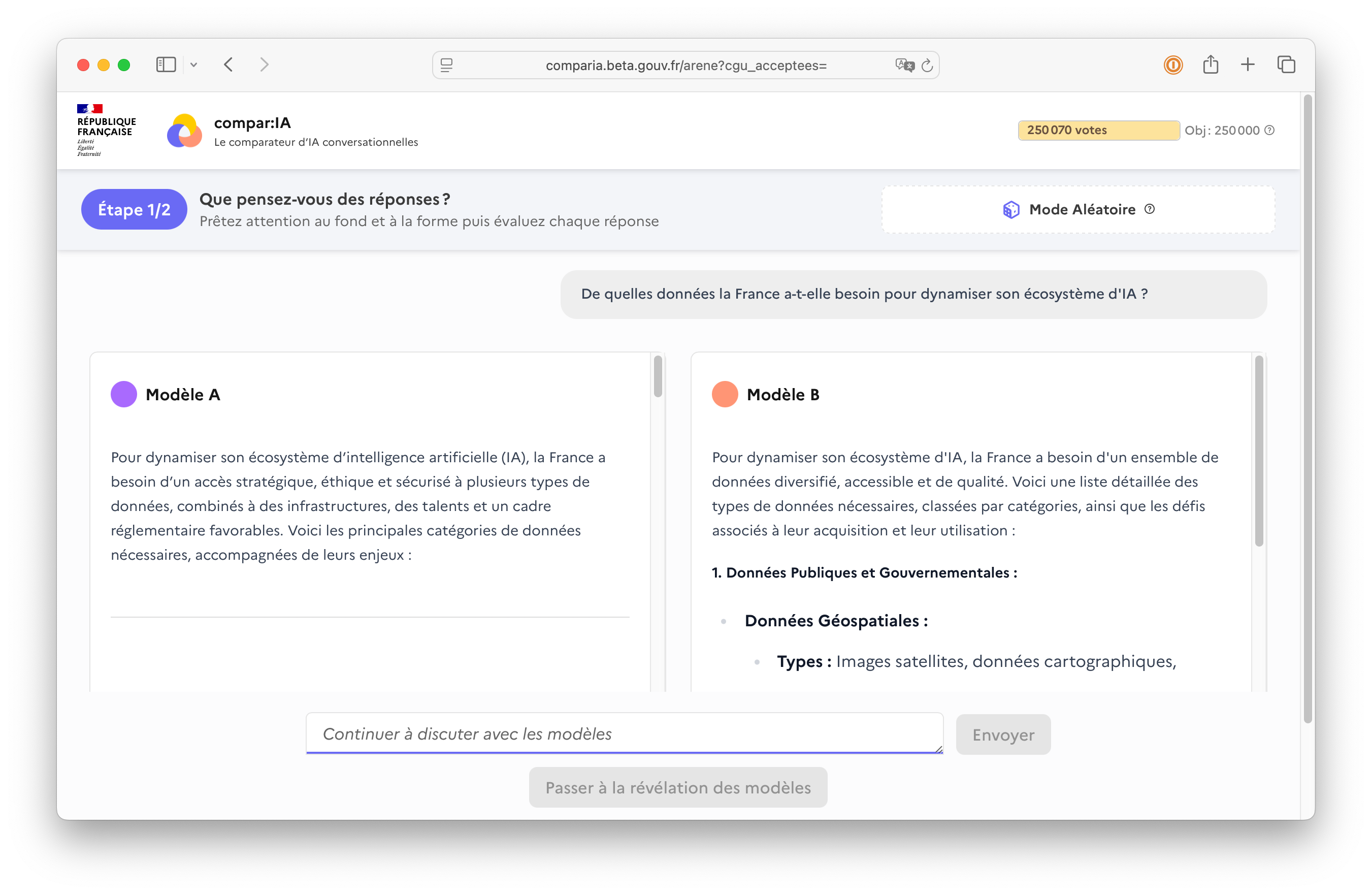
With government funding they built Compar:IA: a platform to collect French-language prompts from real users, and to have those users evaluate the output of different (open) LLMs. Not a new idea, but very well executed.
The result: 600,000 prompts and 250,000 evaluations from real people, largely in French. Open source and available to everyone (HuggingFace, arXiv). A dataset that allows any language model to learn French better and gain knowledge about French culture. And because it’s open source, applications for science and commerce will emerge that we haven’t even thought of yet.
I hope that with a new cabinet, alongside a focus on sovereign IT and GPUs in Groningen, there will also be much more attention for investing in high-quality Dutch-language datasets.
This post was translated from the original Dutch with the help of GPT-5.2.