“Data!”
Ik heb altijd hetzelfde antwoord als mij gevraagd wordt wat voor investeringen er nodig zijn om Nederlandstalige AI verder te helpen. Data.
GPUs zijn fijn, maar daarvoor hoef ik niet in Groningen te zijn. Ik kan nu ook al terecht bij bestaande Europese “AI-fabrieken” zoals de MareNostrum5 supercomputer in Barcelona. Goede en grote hoeveelheden Nederlandstalige data is wat we écht nodig hebben. En die hebben ze Barcelona dan weer niet.
Elke publieke investering in open Nederlandstalige data versterkt het hele Nederlandse AI-ecosysteem en verdient zich vele, vele malen terug. Een veel betere investering dan nog meer GPUs in een datacentrum hangen of de zoveelste “data space”-website oprichten om bestaande datasets nog een keer te recyclen achter een inlogmuur.
Wat voor data moet dan je maken, en hoe kom je daar aan? Nou, kijk bijvoorbeeld naar wat de Fransen doen.
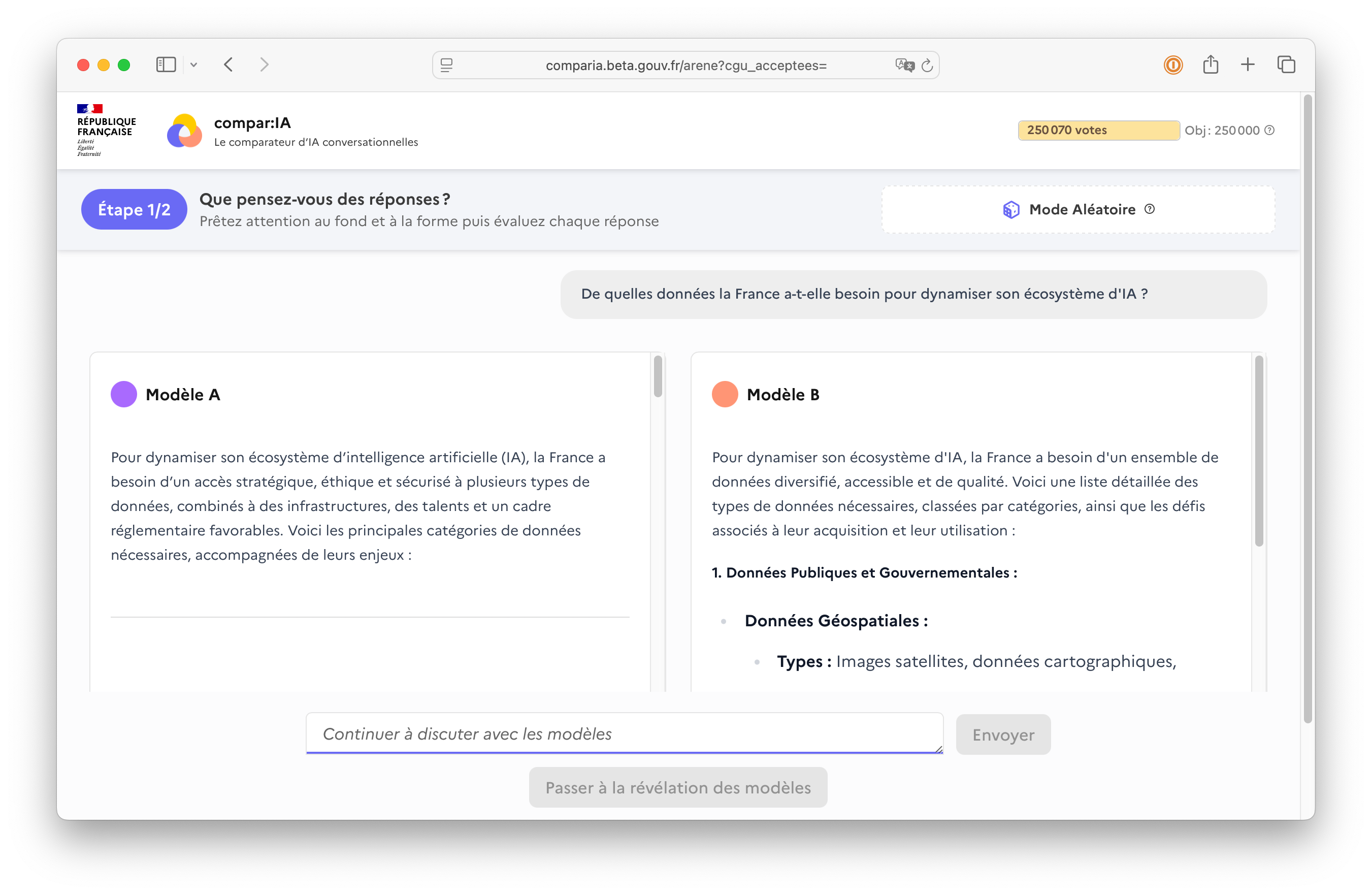
Ze hebben met overheidsgeld Compar:IA gemaakt: een platform om Franstalige prompts van echte gebruikers te verzamelen, en die gebruikers ook de output van verschillende (open) LLMs te laten beoordelen. Geen nieuw idee, wel strak uitgevoerd.
Het resultaat: 600.000 prompts en 250.000 beoordelingen van echte mensen, voor het overgrote deel in het Frans. Open source beschikbaar (HuggingFace, ArXiV) voor iedereen. Een dataset waarmee elk taalmodel beter Frans kan leren en kennis over de Franse cultuur op kan doen. En omdat het open source is, zullen er ook toepassingen voor wetenschap en commercie ontstaan die we nu nog helemaal niet bedacht hebben.
Ik hoop dat er met een nieuw kabinet naast een focus op soevereine IT en GPUs in Groningen ook veel meer aandacht komt voor het investeren in hoogwaardige Nederlandstalige datasets.